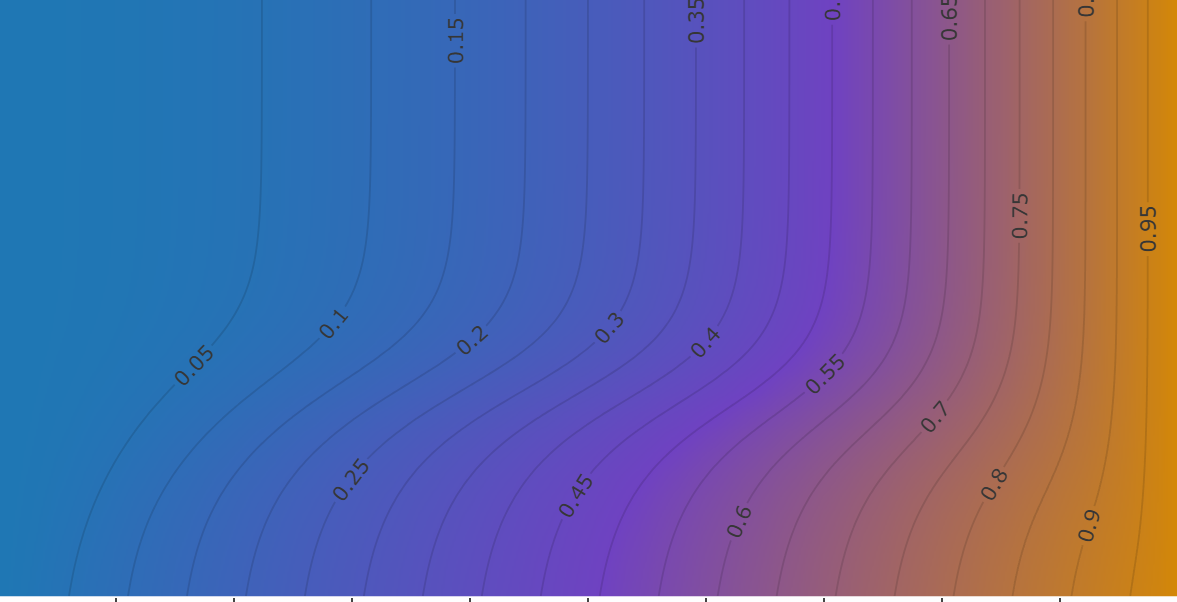
PWM 频率对电磁铁电流与功耗的影响
从 LR 电路微分方程推导 PWM 周期稳态下的峰谷电流、平均电流与平均功耗,并通过交互图表分析频率、占空比和时间常数的影响。
Plotly 交互图表测试
使用 Plotly 绘制交互式正弦函数图表,通过滑块实时调整振幅和频率,并演示 Hexo 文章中的图表嵌入与多语言标签。
龙格-库塔法求解常微分方程
介绍使用龙格-库塔法数值求解常微分方程的原理、离散公式、误差分析与实验结果,并结合完整报告展示具体计算过程。

从微积分和线性代数的角度理解最小二乘法
分别从微积分和线性代数角度推导最小二乘法,解释误差平方最小化、正规方程,并说明解的存在性与几何投影观点。

GAMES101 学习笔记1
整理 GAMES101 学习中的若干重点,包括三维旋转、坐标变换、投影、光栅化、插值和图形学相关数学推导。
USACO23JAN Find and Replace S(洛谷 P9013)题解
讲解 USACO Find and Replace 的图论解法,包括字符映射、环的处理、特殊情况、最少替换次数与代码实现。
![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
[Stanford CS144] Lab4 实验记录
记录 Stanford CS144 Lab 4 的实现过程,将 TCP 发送端和接收端组合为完整连接,并梳理状态转换与报文处理。
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)
[Stanford CS144] Lab0-Lab3 实验记录
记录 Stanford CS144 Lab 0 至 Lab 3 的实现思路,涵盖字节流、重组器、TCP 接收端与发送端等核心组件。
CF1774C 题解
讲解 Codeforces 1774C 的动态统计思路,通过维护二进制串最后一次变化的位置计算每个前缀的可能赢家数。
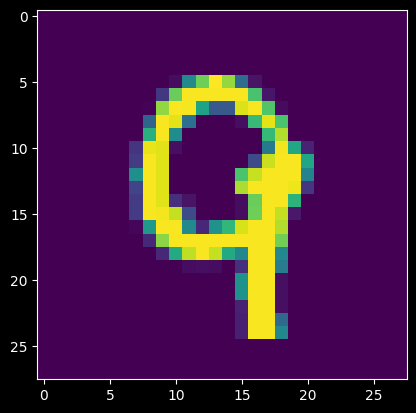
反向传播(Backpropagation)算法学习笔记,基于全连接神经网络
推导全连接神经网络的反向传播算法,并以 MNIST 手写数字识别为例实现前向传播、梯度计算与训练过程。

Ray Tracing : The Next Week 学习笔记(1)
记录《Ray Tracing:The Next Week》的学习与扩展实现,涵盖 BVH、纹理、柏林噪声、实例变换、体积雾和多线程。

Ray Tracing in One Weekend 学习笔记(2):相机类的实现
讲解《Ray Tracing in One Weekend》相机类的实现,包括相机定位、视场角、光圈、焦距与景深效果。