浅谈函数调用的实现
upd@2022/12/18:感谢@adpitacor和@iterator_traits在评论区中指出的几个错别字,现在已经修正
upd@2022/11/24:这篇文章能入选洛谷日报我也是很惊喜。同时深感以前写的东西水平不太行,不过既然入选了日报,还是希望尽量能把文章的水平提高一点的。显然我不可能把整个文章重写一遍,但是可以加入一些自己这段时间新学到的东西,比如栈溢出攻击和 backtrace 的实现,所以赶在发表之前把他们添加了进来。
除了内容上的变化,这次更新还修复了一些错别字,这主要需要感谢 @cancan123456 在洛谷评论区的提醒。文章发出后有很多洛谷的朋友在评论区提醒和提出建议。比如 @szTom指出了 __fastcall 的影子空间。@LiuTianyou 介绍了强制内联的方法(这次新加的内容就使用了强制内联,以前属实是太菜了不知道有这个东西),以及调用约定中的 thiscall。@小菜鸟 提到了 longjump 函数(和本文中的一次返回多个函数有关)。 非常感谢这些网友,在学会了这些东西后我会考虑把它们陆续加进来,如果你有别的任何建议也欢迎像他们一样在评论区提出。此外,我希望这篇文章尽可能的易懂,所以如果文章中有语言模糊不清或是过于简洁影响理解的地方,欢迎以任何方式联系我修改。
1:函数调用是如何实现的?
1.1:一个小例子
1 |
|
观察这样一段程序,在主函数中会调用一个 add1 函数,对于 add1,它又会去调用一个 add2,然后返回计算的结果,最后才在主函数中执行 printf。
把这段程序中函数执行完成的顺序: ,和开始执行的顺序: 列出来就可以发现。更早开始执行的函数更晚结束,这是因为先开始执行的函数需要用到后开始的函数的结果,所以必须先运行完后开始的函数。
这似乎是一个栈的结构,也就是先进后出的结构,对应到函数调用的场景下,就是先开始执行的就要后结束执行。后开始执行的函数先结束执行。
因为函数调用和栈的相关性,我们可以把每一次函数调用抽象成栈中的一个元素。每次我们都执行栈顶上的函数,如果遇到新调用的函数,就把他推入栈中。而每当一个函数执行完了,就把他弹出栈。
具体可以参考下面这个我用 manim 制作的演示视频:
1.2:栈帧
1.2.1:基本结构
前面说到可以把函数调用抽象成栈里的一个元素,这个元素就被称之为栈帧 (stack frame),那我们具体要往栈帧里放什么,才能让 cpu 读取了栈帧数据之后就能正确运行函数呢?
首先,在函数中,我们可能会申明一些局部变量,如果我们想要成功的调用一个函数,肯定需要访问函数中的局部变量。
对于传进来的参数,其实也可以看作时一种局部变量。
其次,我们调用的函数执行完之后,需要返回。可是在返回时,计算机并不知道具体应该返回到哪条指令。用前面的例子说,main 函数调用了 add1,可是当 add1 返回的时候,不知道接下来应该执行 printf 还是直接在 main 中 return 0 了。所以我们还需要在栈帧中存一个返回的位置,也就是返回之后应该执行哪条指令。
最后呢,就像在用数组模拟栈的时候一样,需要标记栈的栈顶,这样才知道下一个数据往哪里放。对于单个栈帧,除了栈顶(结束地址),还需要知道这个栈帧的 “栈底(起始地址)”,通过这个起始地址,我们才能知道在弹出这个栈帧的时候,要弹到哪里。
在 x86/x64 架构的计算机中,有两个专门的寄存器来标记当前函数栈帧的起始地址和结束地址,分别为 xbp (base pointer 栈基址/帧指针,本文称之为帧指针) 和 xsp (stack pointer 栈指针)。其中的 x 代表这个字母会变化,它代表的计算机的位宽,如果是 64 位的机器,那就是 rbp 和 rsp,而 32 位机器的是 ebp 和 esp。
下面这张图[1]很好的解释了栈帧在栈中的具体结构:
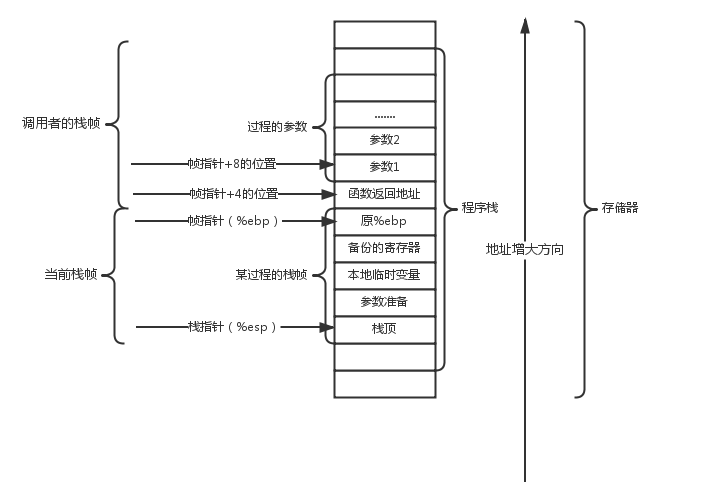
注:栈的增长方向是高地址到低地址,也就是调用者栈帧的地址比被调用者栈帧的小。
图片的上半部分是调用者的栈帧,可以看到里面存有参数(也就是一种局部变量)。也有当前函数的返回地址,通过这个地址可以找到当前这个函数运行完了应该返回哪里。
返回地址是通过当前栈帧的帧指针确定的,它总是储存在当前帧指针 +8 的位置(在 64 位机器中,如果是图中的 32 位,那就是 +4 的位置)。
下半部分存的是当前函数的栈帧,里面同样存有局部变量。ebp 和 esp 分别标注了这个栈帧的起始和结束位置。
通过帧指针加上一些偏移量,就可以访问到这个栈帧里的局部变量。
1.2.2:调用函数时栈帧的变化
- 在调用一个函数时,我们先把函数的返回地址(也就是执行调用时 pc[2] 的值)压入栈中。
- 为了确保返回时能恢复当前帧指针的状态,还需要把帧指针压入栈中。
- 做完了准备工作,可以加入被调用函数的栈帧了。新栈帧当前还没有存放任何数据,所以起始地址和结束地址都是旧栈帧的结束地址。为了达到这一点,需要把帧指针的值(新栈帧起始值)设置成栈指针(老栈帧结束值)的值。
- 现在要把数据存入新栈帧,首先会需要更新栈指针的值,扩大栈的范围,因为栈帧是向低地址增长的,所以要根据局部变量及参数的大小,把栈指针的值减小一些。
- 栈帧已经有了足够的空间,可以放入局部变量并且执行这个函数了。至此,新栈帧的插入完全完成。
1.2.3:函数返回时栈帧的变化
- 函数返回首先要释放之前占用的所有内存,所以我们直接把栈指针设置成帧指针。也就是把栈帧的结束地址直接改成开始地址,相当于撤销调用函数时的第 4 步。
- 现在需要用到之前备份的原帧指针来恢复函数调用之前的状态。我们需要从栈中弹出这个原帧指针,然后复制到帧指针寄存器。
- 弹出返回地址,赋值到 pc。
- 根据 pc 的值,继续执行原函数。
1.2.4:视频解释
看文字解释可能不是很清楚,可以参考下面这个我用 manim 制作的演示视频。演示的是下面这个 C 程序运行时栈帧的变化。
为了演示和理解的方便,假设以下程序中每一行就是 cpu 执行的一条指令,在汇编中实际需要执行更多的步骤(后面会讲)。
1 | int add(int a, int b) |
1.2.5:Talk is cheap. Show me the code.
虽然前面的解释和视频已经能让大部分人了解函数调用的原理了。但要想要深入了解函数调用的详细过程,还是得看编译后的汇编代码。不过不用担心你看不懂汇编代码,我在这部分写了非常详细的解释。
1.2.5.1:如何查看汇编代码
这里介绍两种查看 C 或 C++ 代码对应的汇编的方法:
- 如果你使用的是 gcc 编译器,可以直接在命令行输入
gcc -S [文件],不过默认输出的汇编是 at&t 风格的,我个人比较喜欢 intel 风格的汇编,如果你也希望输出 intel 风格的汇编,可以加入编译选项-m asm=intel - 直接使用编译器输出汇编可能会包含很多跟系统有关,但是和你的程序无关的代码。而且如果你对汇编不是很熟悉的话,可能不知道 C 里面的一行代码对应的是哪几行汇编代码。这里强烈推荐一个网站,叫做 Compiler Explorer,可以解决这些问题。
1.2.5.2:Compiler Explorer 的基本介绍
进入这个网站,基本的界面是这样的:
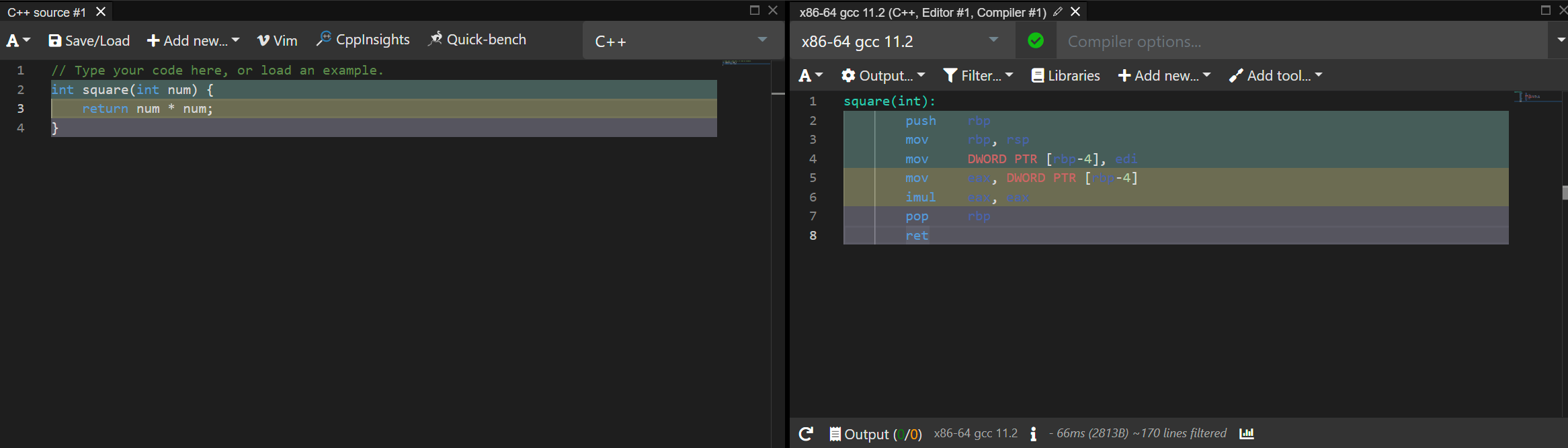
这里只讲几个比较基本的选项,但是这个网站的功能是非常强大的,完全是一个线上的 IDE,具体可以看这个视频

可以看到从左到右有一些选项被框起来了,他们的功能分别是:
- 开启 vim 模式,可以用 vim 的方法编辑代码
- 选择语言,Compiler Explorer 支持 30 多种语言
- 选择编译器/解释器,顺便提一嘴,这网站能选的 C/C++ 编译器非常多,能支持包括但不限于 Xtensa 这种嵌入式的 cpu,或者 IBM power 架构的 cpu。
- 输出选项,可以在这里切换 intel/at&t 格式的汇编,也可以选择输出二进制文件
- 过滤器选项,可以过滤掉和你代码无关的内容
- 添加编译选项
- 通过链接分享
再回到这张图:
可以看到左边的 C++ 和右边的汇编代码都被用不同的颜色标注了起来,被同个颜色标注的代码就表示它们是对应的。
1.2.5.3:分析函数调用的汇编
先放代码:
1 | add: |
1 | int add(int a, int b) |
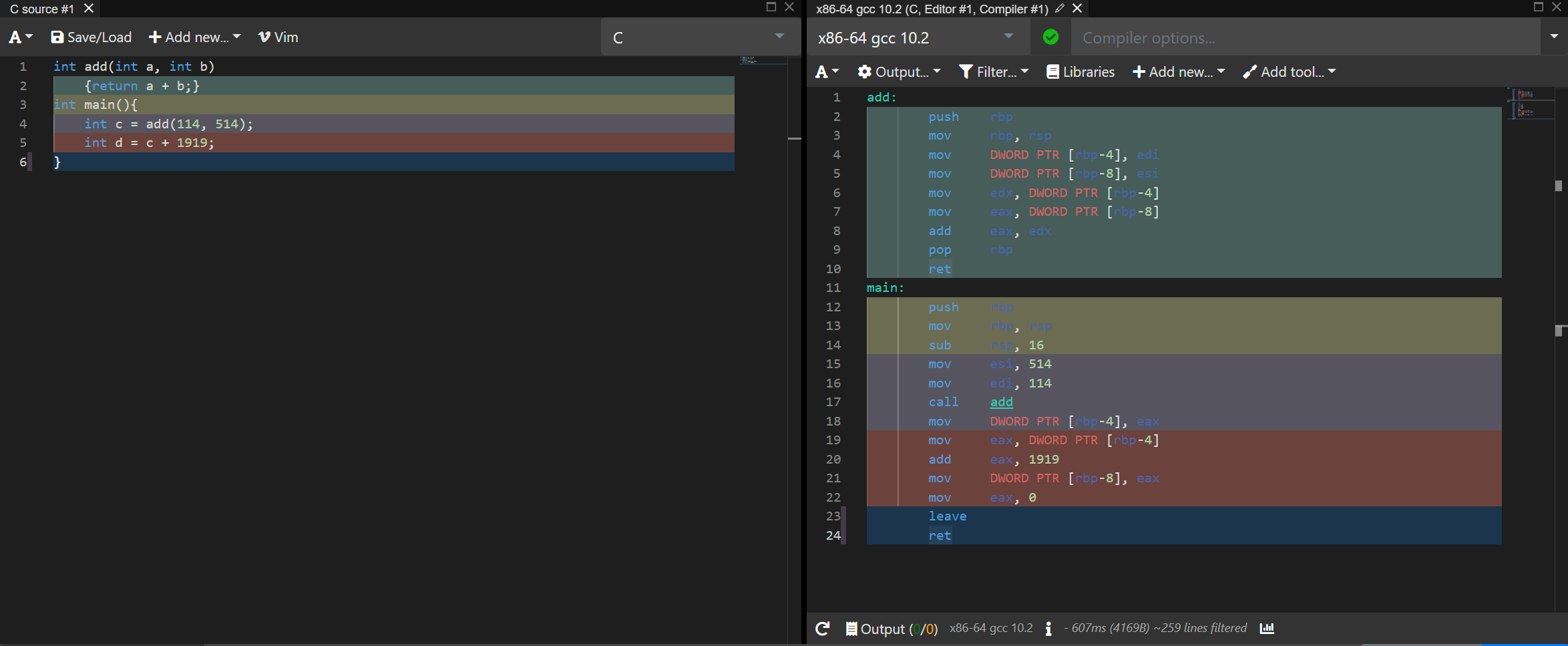
在 main 函数中,我们直接通过 int c = add(114, 514); 调用了 add 函数,在 C 中,看似一行指令就能成功调用函数,但这一句话实际需要下面的汇编来实现:
1 | mov esi, 514 ; 把 514 赋给 esi 寄存器,用于给 add 函数传递参数 |
这段代码中的前两个 mov 指令都是比较容易理解的,但是 call 指令一句话却做了两件事情。
首先,call 会把 call 指令执行时的 pc 压入栈中(这个程序中就是 mov DWORD PTR [rbp-4], eax)。然后,它会把 pc 的值改成 add 函数的起始地址。(pc 存的是 cpu 执行的下一条指令的地址)。然后 cpu 就会开始执行 add 函数。
call 的下一句可能比较难以理解,特别是 DWORD PTR [rbp-4]。其中的 DWORD 表示的其实是一种数据类型,WORD 表示的是两字节的整数,DWORD,也就是 double word,表示的就是四个字节的整数,所以 DWORD 其实就是 C 中的 int。
PTR 跟 C 中的解指针操作很像。mov DWORD PTR [rbp-4], eax。 这一句话就是把 eax 寄存器的值复制到内存中地址为 rbp-4 的位置。并且这个值是四个字节的。所以 eax 的值会被赋值到地址为 rbp-4 到 rbp 的这个范围的内存。
注意 rbp 就是前面说到的帧指针,它保存的是栈帧的开始地址,在函数中,局部变量都是通过帧指针来访问的。而 eax 保存的是 add 的返回值。所以这句话转换成 C 语言就是把 add(114, 514) 的返回值保存到局部变量 c。
现在再来看 add 函数中的内容:
1 | add: |
你可能会感到奇怪,在之前的解释中,sp 指针会先被减去一个值来分配栈帧的空间。在返回时,sp 的值会被设成 bp 的值来释放栈空间。而在上面的代码中,这些操作都没有被执行。
这一系列骚操作其实都是编译器干的,编译器会优化掉一些不必要的操作。对于第一个操作,sp 指针可以告诉我们下次增加栈帧的时候应该往哪加,防止把之前的栈帧覆盖掉,但是这个 add 函数没有调用任何别的函数,也就是不需要再它的基础上增加任何栈帧,所以给 sp 减一个值来分配空间自然就没有必要了。
对于第二个操作,因为 sp 一直没变,自然也无需在返回时更改 sp 的值。
如果你有兴趣,可以去 Compiler Explorer 的网站上加一个 o2 的编译选项,看下我们平时常用的 o2 优化到底是怎么实现的。如果你去看了,发现编译器居然会提前把 114 + 514 + 1919 的值算好,然后就不调用 add 函数了。。。
假设我们把这个 add 函数改成一个递归的函数,那么刚刚的那些优化就不能加了,要不然就会把之前的栈帧覆盖掉。可以看下这个例子。注意其中的 leave 指令会干两件事。第一是把栈指针指向帧指针(帧指针和栈指针相等就表示当前栈帧没有数据),用于恢复之前分配的内存,第二是恢复备份的栈指针。相当于是 mov rsp, rbp 和 pop rsp 的结合。
1.3:不同的函数调用约定 (calling convention)
看了刚刚的汇编代码,你可能会好奇,有很多种方法可以实现汇编中的函数调用,为什么编译器采取的就是这样特定的一种。比如为什么函数的参数是由 edi 和 esi 寄存器来进行传递的,不是直接压入栈中或者是用别的寄存器来传,又比如栈帧的释放工作既可以由被调用者完成,也可以由调用者完成,但为什么在刚刚的汇编代码中,是让被调用者来释放栈帧的。
其实,这些看似玄学的问题都是有答案的,答案就是函数调用的约定。
函数调用约定,是指当一个函数被调用时,函数的参数会被传递给被调用的函数和返回值会被返回给调用函数。函数的调用约定就是描述参数是怎么传递和由谁平衡堆栈的,当然还有返回值。-- 百度百科
所以这里就来介绍几种比较经典的函数调用约定。如果你自己想要写汇编的话,也可以遵守这些函数调用的规则。
1.3.1:x86(32位机)的函数调用约定
还是先介绍下查看 x86 汇编代码的方法。gcc 编译器默认输出的汇编是 64 位的,如果想让 gcc 输出 32 位的汇编代码,需要加入 -m32 编译选项,经测试,可以在我的电脑中输出 32 位程序(我的电脑用的是 MinGW),也可以在程序中加入 __cdecl 或是 __stdcall 这样的指令来指定函数调用约定。不过在 Compiler Explorer 中,就有些奇怪了,即使加入了 -m32 的编译选项,还是不能指定函数调用约定,所以我把 Compiler Explorer 的编译器换成了 msvc(用 Compiler Explorer 是因为分享代码很方便)。如果你知道为什么在 gcc 中指定了函数调用约定就过不了编译,欢迎在评论区告诉我。
为了对比不同函数调用约定的具体区别,我使用了同一段代码。然后再在 add 函数的前面加入不同的函数调用约定。这里附上 Compiler Explorer 的链接
1 | int add(int a, int b, int c) |
如果想要指定函数的调用方法为 cdecl,需要这样申明函数:int __cdecl add(int a, int b, int c)。
cdecl 是 C 语言的默认函数调用方法(32 位时)。它的特点由如下几个:
- 参数通过栈来传递,并且参数由右向左被依次压入栈中。
- 由调用者负责释放被调用函数占用的内存。或者说手动清栈。
- 整数返回值存 ax 寄存器上,浮点型返回值存在 st0 寄存器上。
前面的代码使用 cdecl 约定生成的汇编如下:
1 | _a$ = 8 ; size = 4 |
注意这几句话:
1 | push 1919 ; 0000077fH |
可以看到函数的参数是以从右到左的顺序被压入栈中的。因为使用了 push 指令,在把数据存入栈中的时候就已经减少了 esp 的值,所以你会发现 add 函数中没有减少 esp 指针的值来开辟内存。
和之前分析函数调用原理的那部分一样(见1.2.5.3),这个函数调用没有备份 ebp 也是因为 add 函数没有调用别的函数,所以被编译器优化掉了。
而 add esp, 12 这句话的作用是释放 add 函数占用的内存。并且这句话是出现在 main 函数中的,可以说明 cdecl 的特点,也就是由调用者来释放内存。
那么这样的约定有什么好处呢?
它最主要的好处就是可以采用变长参数(参数的数量不固定)。我们在 C 中最常使用的变长参数函数就是 printf() 和 scanf()。printf 的函数申明是这样的:int printf (const char *__format, ...) 后面的那三个点就代表变长参数。如果你对这样的可变参数有兴趣,推荐去看一看这篇洛谷日报。
如果一个程序中有很多地方调用了可变参数函数,每个位置传进去的参数数量可能是不固定的,这就让在可变参数函数内部释放内存变得不现实了。因为在这个函数内部只能释放固定容量的内存,而每次调用需要释放的内存是不同的。如果是让调用者来释放内存的,就可以根据每次调用的参数数量和大小来决定具体要释放空间了。
(当然,你也许可以通过某个寄存器传入需要释的内存大小,或者让被调用函数释放固定的那一部分参数,再让调用者释放可变的那部分参数,不过现在还没有这样的函数调用规则,所以只能在直接编写汇编的时候这样做,而不能在 C/C++ 中指定这样的函数调用约定)。
如果想要指定函数的调用方法为 stdcall,需要这样申明函数:int __stdcall add(int a, int b, int c)。
stdcall 是绝大多数 Win32 API 使用的函数调用约定。它的特点由如下几个:
- 参数通过栈来传递,并且参数由右向左被依次压入栈中。
- 被调用函数负责释放被调用函数占用的内存。或者说自动清栈。
- 其他的特点基本跟 cdecl 相同。
前面的代码使用 stdcall 约定生成的汇编如下:
1 | _a$ = 8 ; size = 4 |
从下面这几句话可以看出,stdcall 的压栈顺序和 cdecl 完全一样,也是从左到右的:
1 | push 1919 ; 0000077fH |
接下来就是和 cdecl 不同的地方了。注意这一句出现在 add 函数中的话:ret 12 它代表着先 add esp, 12 再 ret 0。也就是先释放掉 12 字节的内存,然后再返回。这句话说明了在 stdcall 中,函数占用的栈是由函数自己释放掉的。
这样做的主要好处就是可以节省程序的大小。如果参数数量一样的话,清栈就是一件重复的事情,没必要每次调用都多写一句话来清栈,直接在函数内部释放空间就好了。
如果想要指定函数的调用方法为 fastcall,需要这样申明函数:int __fastcall add(int a, int b, int c)。
fastcall 是一种用于提升函数调用速度的函数调用约定。它会利用寄存器来传递参数。不过,不同于 cdecl 和 stdcall,fastcall 的实现并没有一种明确的标准,不同的编译器可能会编译出不同的东西。以下的特点来自于Visual Studio 2022 的标准。
- 在参数列表中从左到右找出前两个 32 位整数或更小的参数用 ecx 和 edx 寄存器传递。其他的参数以从右到左的顺序通过栈传递。
- 由被调用函数释放内存(同 stdcall)
前面的代码使用 fastcall 约定生成的汇编如下:
1 | _b$ = -8 ; size = 4 |
观察这几句话:
1 | push 1919 ; 0000077fH |
可以看到前两个参数,也就是 114 和 154 都是被寄存器传递的,而最后一个参数,也就是 1919,被推入了栈中。这符合前面提到的第一个特点。
而在 add 函数中的 ret 4 又说明了被调用函数释放了内存。因为只有一个参数是在栈中的,其他两个都在寄存器中,所以这个函数只占用了 4 字节的空间,释放掉的空间也自然是 4 字节。
1.3.2:x64(64位机)的函数调用约定
在 x86 的机器中,一共只有 8 个通用寄存器,这就造成了大部分的函数调用都只能使用栈来传递参数,不过这样的速度是比较慢的。在 x64 平台中,一共有 16 个通用寄存器,比 x86 多了 8 个,充足的硬件资源也让我们有机会使用寄存器来传递参数。所以在 x64 平台上,几乎所有的函数调用约定都和 x86 上的 fastcall 相似,也就是尽量使用寄存器传参。
x64 平台下的函数调用约定主要有微软的调用约定和 System V AMD64 ABI 两种。这里我主要介绍 System V AMD64 ABI 约定。此约定主要在Solaris,GNU/Linux,FreeBSD和其他非微软OS上使用。如果你想了解微软的约定,可以参考这个网页。
这个调用约定的代码我就不放了,因为之前解释栈帧和函数调用原理时的汇编代码遵守的就是这个约定。
这个约定又如下的主要特点:
- 前 6 个整数和指针参数使用 RDI,RSI,RDX,RCX,R8,R9 寄存器以从左到右的顺序传递。
- 前 8 个 float 通过 xmm0-xmm7 寄存器以从左到右的顺序传递。
- 其他参数会被从右到左的压入栈中。
- 被调用函数负责清栈
不过了解了这些函数调用规则又有什么用呢?除了更深入的了解函数调用的实现方法,还可以跨语言的调用函数。函数调用约定详细的规定了调用者和被调用者的职责,也规定了参数的传递方法。这样,只要调用者和被调用者都遵守约定,就可以在一个语言中调用另一个语言写成的函数了。比如在 Python 中使用 Ctypes 库调用 C 函数时,就需要指定函数的调用约定来加载动态链接库(dll 文件)。
此外,还有一些别的函数调用约定,如果你有兴趣,可以参考这几个网页:
- https://docs.microsoft.com/zh-cn/cpp/cpp/calling-conventions?view=msvc-170
- https://www.laruence.com/2008/04/01/116.html
- https://zh.wikipedia.org/wiki/X86%E8%B0%83%E7%94%A8%E7%BA%A6%E5%AE%9A
2:了解函数调用后能搞的一些骚操作
2.1:backtrace (调用回溯?)
2.1.1:简介
这个词我不太清楚准确的中文翻译,下面以调用回溯来指代。
调用回溯是一个常用于调试的方法。想象这样的一个场景:我们的程序运行到了某个地方出现了 bug,这个时候大概是希望知道这个 bug 具体是在哪个函数中出现的。不过这还不够,因为有很多不同的位置可能调用同一个函数,所以我们希望知道函数之间的调用关系。gdb 里的 backtrace (简写为 bt)命令就提供了这种功能。
考虑下面这样一个程序:
1 |
|
add1 函数中尝试取出 0 地址的值会造成段错误(因为 0 就是 NULL),如果我们希望得到这个位置的函数调用关系,就可以先用 gdb 在 add1 上打一个断点,然后使用 bt 命令:
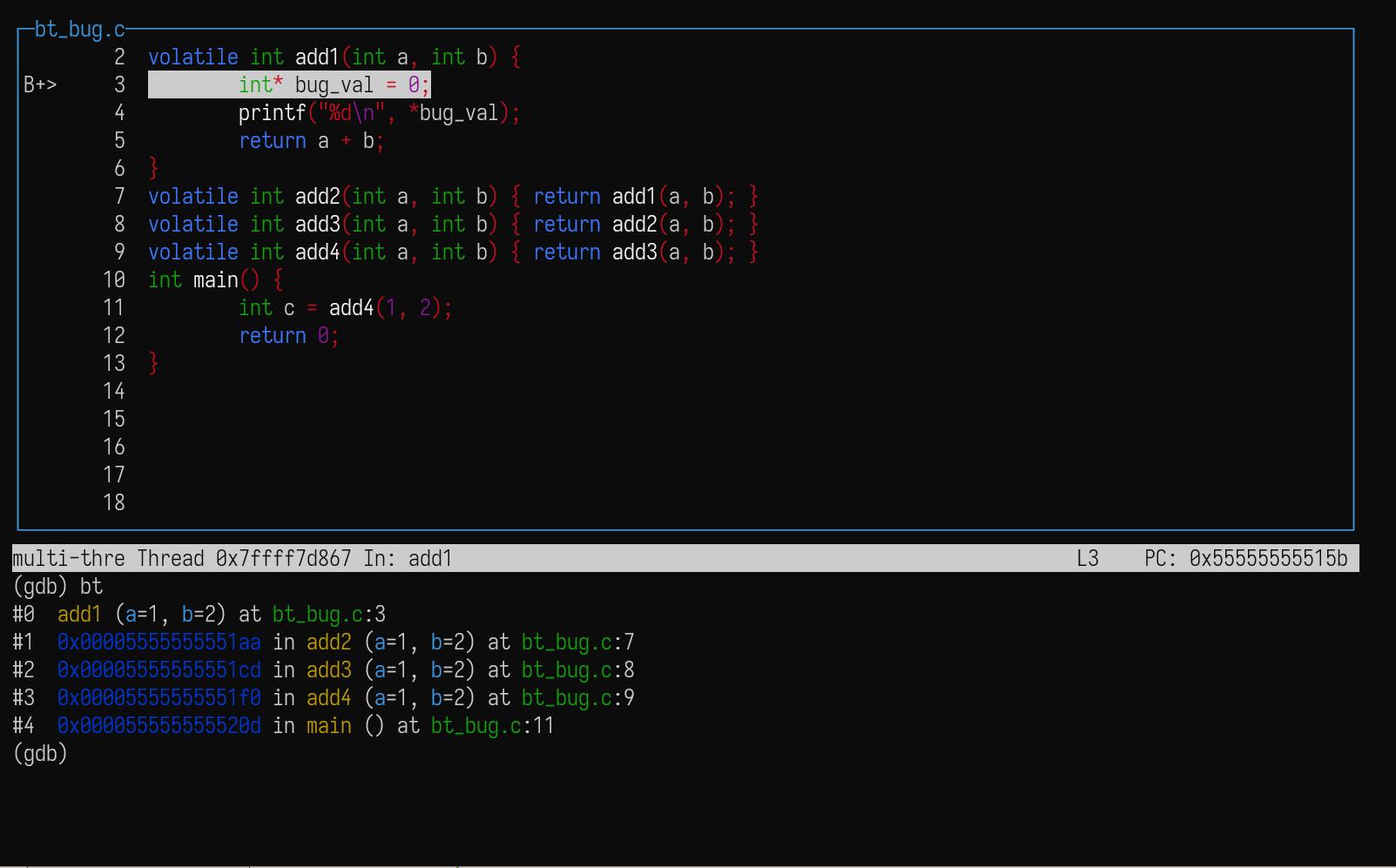
函数关系的信息如下:
1 | #0 add1 (a=1, b=2) at bt_bug.c:3 |
2.1.2: 简单实现
这个功能很很有用,那我们有办法自己写一个吗(可以是简化版的,只需要显示地址)?
仔细想一想的话就可以惊喜的发现,我们需要的信息全部藏在栈帧里。
其实诸如 0x00005555555551aa 这类的地址是某个函数的返回地址。参考栈帧的结构图,这个返回地址储存在帧指针指向位置的向上一个单位(对于 64 位机,就是 bp + 8 字节)。而我们只要遍历栈帧,就可以得到所有的返回地址,也就是函数调用关系。
那如何遍历呢?帧指针指向的位置(bp + 0 字节)其实就储存了上一个栈帧的帧指针。只要递归的去查找上一个栈帧的帧指针,我们就能打印出每个函数调用的返回地址了。此过程很好了体现了 backtrace 或是回溯这个名字。
不过到现在,我们还有两个问题没有解决。
- 我们说要递归的去查找上一个栈帧的帧指针,但是递归的终止条件是什么呢?
- 如何在 c 语言中栈指针,也就是 bp 寄存器的值呢?
对于第一个问题,不同的操作系统有不同的情况。在我的实验环境(Ubuntu 22.04.1 on WSL2)中,这个终止条件是上一个栈帧的帧指针为 0x1 的时候。
我不确定 linux 系统中是否有这样的规定,这个终止条件只是我在调试的时候观察到的。
在别的操作系统中,比如 MIT6.s081 这门公开课使用的教学系统 xv6,栈空间的最大大小就是一个页帧的大小,那么递归到超出该页帧范围的时候就意味着到达了终止条件。
如果你了解一个通用的判断栈帧是否结束的方法,欢迎在评论区留言。
对于第二个问题,一个简单的办法是使用 gcc 的内置函数 __builtin_frame_address,这个函数可以返回当前函数的帧指针。
不过如果你希望体验一下 gcc 的骚操作(这些都没被包含在 c 语言的标准中),可以使用内连汇编,如下:
1 |
|
在 "mov %0, rbp" : "=r"(x) 中,mov %0, rbp 是一个汇编的模板,并不是真正的汇编,这有点类似于 C++ 中的模板,在编译的时候会把类型替换掉。gcc 编译的时候也会把 %0 这个东西替换成后面 : "=r" (x) 规定的变量(这里是 x)所在的寄存器。那么这个内联汇编的意思就变成了:“把 rbp 的值存进 %0 所在的寄存器,其中 %0 会被替换成 x”
如果你对内联汇编有兴趣,可以参考 gcc 的文档,我的这篇文章 中也有些更详细的解释。
上面的代码中,除了这个离谱的内联汇编,还使用了一些很骚的操作:
1 |
单个 inline 关键字只能向编译器建议内联,不保证一定内联[4]。而 __attribute__((always_inline)) inline 就能让 gcc 强制内联。这里的 __attribute__ 还有很多种别的用法,详细内容可以参考文档 和网上的一些博客。
解决这些问题后代码就不是很难了,不过这份代码不可避免的涉及到了很多指针,如果不熟悉的话可以先去学习下。
1 | FORCE_INLINE void* r_bp() { |
2.1.3:加入函数名
刚刚那样的实现只能打印出返回地址,但是 gdb 的调用回溯是可以显示函数名的,那我们有什么办法通过地址显示函数名吗?
一种方法是使用 linux 中的命令行工具 addr2line,其可以把一个地址转化为函数名,不过我在使用的时候出现了一些问题,没有成功。
还有一种方法是使用 backtrace_symbols 函数,这个函数可以把一个地址数组转化为函数名数组,其包含在 execinfo.h 头文件中,如下:
1 | /* Return names of functions from the backtrace list in ARRAY in a newly |
需要注意的是,我们在编译的时候需要加上 -rdynamic 选项,这样才能让链接器把符号加入动态符号表(其实我也不太懂,原文如下)。
https://stackoverflow.com/questions/6934659/how-to-make-backtrace-backtrace-symbols-print-the-function-names
The symbols are taken from the dynamic symbol table; you need the -rdynamic option to gcc, which makes it pass a flag to the linker which ensures that all symbols are placed in the table.
然后就可以写出完整代码了:
1 |
|
用
1 | gcc backtrace.c -o bt -masm=intel -ggdb3 -rdynamic |
编译后,运行 ./bt,可以得到如下输出:
1 | ./bt(add1+0x32) [0x55bfc409e25b] |
最后提一嘴,其实写这些纯粹没事找事,因为 execinfo.h 这个头文件里还有个函数就叫 backtrace()
2.2:栈溢出攻击
注:思路来自这个视频
栈溢出攻击可以在没有显式调用一个函数的时候执行某个函数,比如下面这个程序:
1 |
|
虽然直觉上觉得离谱,但是用下面这个编译选项
1 | gcc stk_ov.c -o stk_ov -fno-stack-protector -ggdb3 -masm=intel |
编译执行后,就会发现 hello world 被打印出来了。这样的现象其实是比较危险的,因为通过修改栈,可以直接执行一些恶意代码。不过现代的编译器也知道这种技巧,所以如果我不开 -fno-stack-protector 这个选项,程序是运行不了的。
所以这个程序到底是如何执行 malfunc 的?把 set_arr() 函数的栈帧画出来就能理解了:
1 | 低地址 |
可以发现,这个 a[3] 刚好指向了储存 set_arr 返回地址的位置,所以我们把这个地方改了,自然就会跳转到 malfunc() 中。那 malfunc 里面为啥要加一个 pop rbp 呢?
其实我也不知道
如果不加这一行代码,在 Compiler Explorer 里是可以正常运行的,具体可以看这个链接。
但是如果不加这一行,在本地用刚刚的编译选项就会产生段错误,具体的情况我写在了这个 StackOverflow 的帖子里,如果你知道欢迎在评论区或者 StackOverflow 上回答。
3:如何写一个不用递归的 dfs 来遍历树
3.1:具体实现
通过刚刚的分析,我们已经非常清楚函数调用的实现原理了。如果要实现一个不递归的 dfs,最简单的方法就是自己模拟汇编中函数调用的过程。
先来看一下一个使用递归的 dfs 是怎么写的,相信大家都很熟悉:
1 |
|
可以看到,dfs 函数中的局部变量或参数有两个: cur 和 fa 分别表示当前节点和父节点
回想一下一个栈帧的结构,里面包含着局部变量,备份的 bp 以及返回地址(调用时的 pc)。其中,备份的 bp 是为了让 bp 回到调用者的状态而准备的。调用者者需要通过 bp 来正确的访问局部变量。不过,我们可以把单个栈帧封装成一个结构体,然后把整个栈当作类型为栈帧类的数组,再用数组来模拟栈。这样,不需要存 bp 也能正确的访问每个栈帧里的局部变量了。
可以这样写这个结构体来代表栈帧,里面只包含 pc 作为返回地址(或者说当前这个函数执行到了哪里)和局部变量(参数)。对于 dfs,必须要备份 pc 的值,因为当前这个函数还没执行完就要去执行下一个函数了,等到被调用的函数执行好时,我们需要备份的 pc 来继续执行当前的函数 (而不是从头开始执行当前函数):
1 | template <typename PARA_TYPE> // PARA_TYPE 是参数的类型 |
然后通过这个结构体来模拟栈的操作:
1 | template <typename FRAME_TYPE>//栈帧的类型 |
最后,还有这个结构体,相当于把前面的两个结合了一下
1 | template <typename PARA_TYPE> |
有了这些结构体,要如何在 dfs 函数中使用呢?只要模拟汇编中函数调用的过程,就一定不会出问题,我们可以根据下面这些条件来写出非递归的 dfs。
- 如果要调用函数,直接把新的栈帧推入栈中,也就是使用
Func_stk的call函数 - 如果要返回当前的函数,就弹出一个栈帧,也就是使用
Func_stk的ret函数 - 其他的情况下,按照当前的 pc 值执行不同的语句
- 每执行完一条语句 pc 就要 +1
根据 pc 执行不同的语句可以这样实现
然后就可以写出下面的代码:
1 | void dfs(int cur, int fa){ |
下面是完整代码,欢迎大家赋值下来去自己的电脑上试一试:
1 |
|
3.2:小优化
观察原来的 dfs 函数
1 | int dfs(int cur, int fa){ |
不难发现新调用的函数和当前函数有一个相同的参数,那就是 cur。也就是说,下一个被调用的函数的 fa 参数就是当前函数的 cur 参数。所以我们完全可以在判断 nex != fa 的时候不适用 fa,而是直接去访问上一个栈帧中的 cur 参数,具体写法的话,可以把 fa 改成这样:dfs_stk.stk[dfs_stk.sp-1].paras(paras 是一个 int,因为不需要再在参数中包含 fa 了)。
这样就可以省下一部分空间了。
3.3:所以,有什么用??
纯教学意义,加深对于函数调用实现原理的理解,没有实际用途其实还是有点用的
3.3.1:测试方法
为了更准确的对比非递归 dfs 和正常的写法,我使用 python 加洛谷的 CYaRon 测试数据生成器(强烈推荐,真的方便)生成了 10 个测试点。每个测试点都是一个节点数量为 的树。
输入数据生成器的代码:
1 | from cyaron import * |
答案生成器:
1 |
|
随后在洛谷上开了个题目,然后把数据传上去了。之后所有的测试均使用这个题目。
3.3.2:空间?
理论上来说,经过刚才的优化,非递归 dfs 的空间占用应该会比正常写法小大约 4MB (每个栈帧中都少了一个 int,最多能有 个栈帧),以及 bp 的大小(见前文,使用结构体封装栈帧,不需要记录 bp)。
想到这里,我赶紧去把常规写法的 dfs 交了一下,以便等下可以对比数据来体现我这个写法的高明。
结果如下:
| 时间(s) | 空间(MB) |
|---|---|
| 9.06 | 55 |
详见提交记录
那实际上呢?
一顿操作猛如虎,一看空间 62(MB)。一顿操作猛如虎,一看时间 9.2(s)
不仅空间不降反增,时间也更长了。
详见提交记录
为啥呢?
经过我一段时间的思考,感觉多出来的空间占用是栈的问题。虽然单个栈帧占用的空间更少了,但我是使用数组模拟栈的,弹出的栈帧不能被释放掉,而是还留在内存中。而且很多开出来的内存是空的,并没有被使用。在常规的 dfs 中,弹出一个栈帧后,内存立刻就被释放掉了。可是如何证明这个呢?也许我可以不使用数组模拟栈,而是使用一个真正的栈,只要一个栈帧被弹出,就把它占用的内存释放掉。
要达到这一点,可以选择 stl 的 stack。事实证明,使用 stl 后,空间占用和常规的写法完全一样,可是时间就比较一言难尽了,毕竟是 stl,达到了 10.26 秒。提交记录
至于为什么没有比常规的写法占用更少的内存,我就不是很清楚了,如果你知道,欢迎在评论区告诉我。
2.3.3:时间?
现在我们已经了解了空间占用的问题,可为什么时间会更慢呢?理论上来说,这样模拟的函数调用,应该会比正常写法的 dfs 快一点。因为我弹出或者推入一个栈帧只需要把栈顶指针 ++ 或者 --。而常规的 dfs 则需要一堆繁琐的步骤(见 1.2.2 和 1.2.3)。
我想了挺久还是没想出来,还是看下汇编吧。
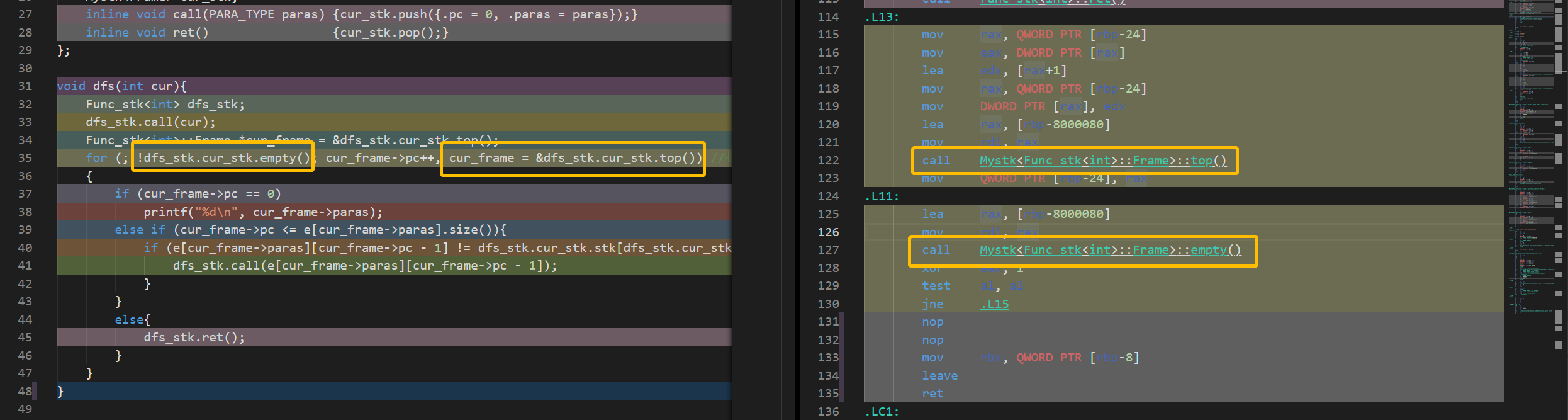
左边和右边被我圈出来的是互相对应的代码段,乍一看这好像也没什么问题,函数在汇编里被正确调用了。
可是我明明在写这些函数的时候加了 inline[3] 啊(如下图)。
1 | inline FRAME_TYPE& top() {return stk[sp];} |
如果说 inline 没起作用的话,那化简掉的函数调用在这里就还回来了,甚至还增加了函数调用。
这也提醒了我们,inline 关键字只是建议编译器把函数改成内联函数,如果编译器觉得函数比较复杂,是可以不内联的。(但是这函数真的超级简单啊,为什么不内联。。。)
所以我把这些内联函数全部换成了宏定义,这样就是真正的“内联”了,效果如下:
| 时间(s) | 空间(MB) |
|---|---|
| 8.83 | 63.16 |
提交记录
提升了 0.2 秒左右。不过为了这 0.2 秒多写几十行代码就。。。
3.3.4:骚操作
3.3.4.1:一次返回多层函数
我们知道在常规的 dfs(或是其他递归函数)中,return 一次,只会返回到调用这个函数的函数。这是因为执行一次 return 会弹出一个栈帧。但既然我们能通过模拟栈帧的方法,完全把函数调用的过程掌握在我们自己的手中,为什么不能一次弹出多个栈帧呢?虽然听起来挺离谱的,但是也许在某些时候会有些用处。
比如,如果我们想通过递归来暴搜出某一个答案,现在在某一层递归中,答案已经找到了。正常情况下,我们需要一层一层的退出递归调用。而使用模拟栈帧的方法,我们可以直接把前面所有的栈帧都弹出,或者更直接一点,直接从模拟栈帧的循环中 break出来。
为了测试这个骚操作对性能的提升,我又在洛谷上传了一道题目。题目大概是给你一个 的网格,每个格子都可以是 或是 ,分别表示不可以走和可以走,问你能否从 ,通过八个方向的移动,到达 。并且,在搜索的过程中,需要按照 dfs 的顺序输出访问的位置。
输入数据生成器如下:
1 |
|
如果使用的非递归的 dfs,在发现能够到达 点之后就可以立刻退出搜索,而正常的 dfs 会需要一层一层的退出。
所以,也许非递归的 dfs 会快一点?
具体的结果可以见下表:
| 常规 dfs | 非递归 dfs+数组模拟栈 | 非递归 dfs+stl stack | |
|---|---|---|---|
| 提交记录 | 记录 | 记录 | 记录 |
| 时间(s) | 7.77 | 9.53 | 10.50(时间超限) |
| 空间(MB) | 512+(内存超限) | 335.54 | 187.01 |
结果还是挺出乎我意料的。在最后一个点中,常规 dfs 因为内存超限被卡掉了,但是前面的点中,常规 dfs 都比非递归的快,不管是用数组模拟栈的还是使用 stl stack 的。
对比 stl stack 的非递归 dfs 和常规 dfs,可以发现在这个问题中,使用非递归 dfs 对节省内存有比较显著的作用。(至于为什么用数组模拟的内存占用看起来很大,已经在前面解释过了)。
不过这些测试还是不能较好的展现逐层返回和直接返回的区别,所以我使用了 chrono 库(精度比 clock() 更高,可以获取纳秒级别的时间)来测量函数返回的时间占用。
结果就比较一言难尽了,高情商的说法是直接返回的返回速度比逐层返回快了约 倍,低情商的说法是逐层返回的时间占用也就 纳秒 ( 毫秒)。当然,函数的返回速度也跟返回值类型有关,每次传递返回值都需要一定的时间,如果递归的层数特别多,并且返回值类型非常大,使用直接返回也许就能产生显著的效果了(这样的情况似乎基本上没有呢)。
3.3.4.2:获取调用者的局部变量以及其他骚操作
这个骚操作已经在前面小优化的部分提到过了,因为所有函数的栈帧都储存在一个栈里,如果你用的是数组模拟栈,那就可以访问到之前被调用的函数的局部变量。在一些场景中,比如之前讲到的树的 dfs 遍历,就可以用到这个方法节省空间。至于别的用途我还真没想到,如果你有想法的话欢迎在评论区分享。
此外,就像是我们能弹出任意数量的栈帧一样,如果你愿意,用模拟栈帧的方法,你还可以在一个函数中同时调用任意数量的函数,也就是压入任意数量的栈帧。当然我也没想出来如何利用这种阴间操作。
3.4:总结
总的来说,非递归 dfs 的教学意义是大于实际意义的。虽然有的时候非递归 dfs 可以带来一些常数提升,但是会需要更多的时间写出非递归 dfs。而且这一点微弱的常数提升在 O2 的加持下也变的没有意义了。除非一个题目非常的卡常,还不能使用 bfs 和 O2,不然最好还是不要写这种奇怪的东西。
所有非递归 dfs 能带来的优化是建立在递归这种特殊的函数调用的基础上的。在递归中,每次函数调用的栈帧都有着相同的结构,相同的大小,所以我们才能使用结构体把栈帧封装起来,并简化函数调用的过程。
之前提到的骚操作也是因为我们对函数调用有了完全的控制,可以随意访问栈中的内存,并且弹出和压入任意数量的栈帧。如果函数调用不是在递归中的,那我们就不知道每个栈帧的长度和结构,自然也没法实现这样的操作。
最后,如果你有问题或是建议,都欢迎在评论区分享或者是联系我。
- 1.来源为:https://www.cnblogs.com/zzdbullet/p/9629909.html ↩
- 2.pc 即 program counter, 程序计数器,它指向下一条指令所在的内存单元的地址,通过 pc,计算机总是可以知道下一步该干什么。 ↩
- 3.在 C/C++ 中,为了解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,特别的引入了 inline 修饰符,表示为内联函数。(相当于把函数内的内容直接放到调用的地方了,免去了函数调用的繁琐过程)。来源 ↩
- 4.你可能在下文中看到我说 inline 没有强制内联,编译器可能不采取建议。这是因为调用回溯这一段是我在 2022 年 11 月新添加的,写后文的时候我还不知道如何强制内联。也感谢 @LiuTianyou 在洛谷的评论区提醒我。 ↩



![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)