upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里:
https://github.com/ttzytt/xv6-riscv
里面不同的分支就是不同的实验。
开始之前先吐槽一句,为什么 xv6 源码的码风这么怪啊???函数的返回类型居然跟函数名不在同一行??
1 2 3 int main (int argc, char * argv[]) }
像这样……
然后就是建议阅读时关闭暗黑模式(右下角齿轮标),因为有些图片上的字是黑的,开了暗黑模式就看不清了。
Lab 1: utils
实验说明地址:https://pdos.csail.mit.edu/6.828/2020/labs/util.html
sleep
sleep 命令,唯一的参数是休眠的时间。
因为有系统调用,所以实现起来还是比较简单的,可以直接调用提供的 sleep 系统调用。
唯一需要注意的是要在 #include user/user.h 之前先 #include kernel/types.h。这个文件里面包含了一些类型的定义,而 user.h 需要用到这些定义。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fd_types.h" int main (int argc, char *argv[]) { if (argc != 2 ){ fprintf (STDERR, "usage: sleep <tick count>" ); exit (1 ); } int tm = atoi(argv[1 ]); sleep(tm); exit (0 ); }
其中的 kernel/fd_types.h 是我自己加的,源码如下,就是简单定义了输入输出的文件标识符,防止自己忘了:
1 2 3 4 #pragma once const char STDIN = 0 ;const char STDOUT = 1 ;const char STDERR = 2 ;
pingpong
创建子进程后,先让父节进程发送一些信息。然后父进程就可以调用 wait() 了。而子进程会先输出 “pong”,然后向父进程发送信息。最后父进程会收到消息,然后输出一个 “ping”。
这个过程看着比较简单,但是因为我一开始不清楚管道的特性,所以没有正确的使用。一般来说管道是用于单向通信的,因为这个 lab 需要父进程和子进程互相通信,所以应该创建两个管道。
这个知乎回答 比较清晰的解释了管道的实现:
数据只能单向移动的意思是FIFO,于是linux中实际构建了一个循环队列。具体一点则是,申请一个缓冲区,作为 pipe() 操作中匿名管道文件实体,缓冲区设俩指针,一个读指针,一个写指针,并保证读指针向前移动不能超过写指针,否则唤醒写进程并睡眠,直到读满需要的字节数。同理写指针向前也不能超过读指针,否则唤醒读进程并睡眠,直到写满要求的字节数。
并且,我一开始没有加 wait(),就会出问题,比如会输出一些乱码。因为我们不知道系统会先执行子进程还是父进程,可能两个进程同时输出 “ping” 和 “pong”,然后这两个词就会混在一起了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include "kernel/fd_types.h" #include "kernel/types.h" #include "user/user.h" enum PIPE_END { REC = 0 , SND = 1 };int main (int argc, char * argv[]) if (argc != 1 ) { fprintf (STDERR, "usage: pingpong (no parameter)" ); exit (114514 ); } int p[2 ]; pipe (p); int cur_pid = fork(); if (cur_pid == 0 ) { char buf[20 ]; if (read (p[REC], buf, sizeof (buf)) > 0 ) { printf ("%d: received pong\n" , getpid (), buf); } fprintf (p[SND], "child" ); exit (0 ); } else if (cur_pid > 0 ) { char buf[20 ]; fprintf (p[SND], "parent" ); wait (0 ); if (read (p[REC], buf, sizeof (buf))) { printf ("%d: received ping\n" , getpid (), buf); } exit (0 ); } else { fprintf (STDERR, "failed to fork" ); exit (1919810 ); } exit (0 ); }
primes
35 35 35
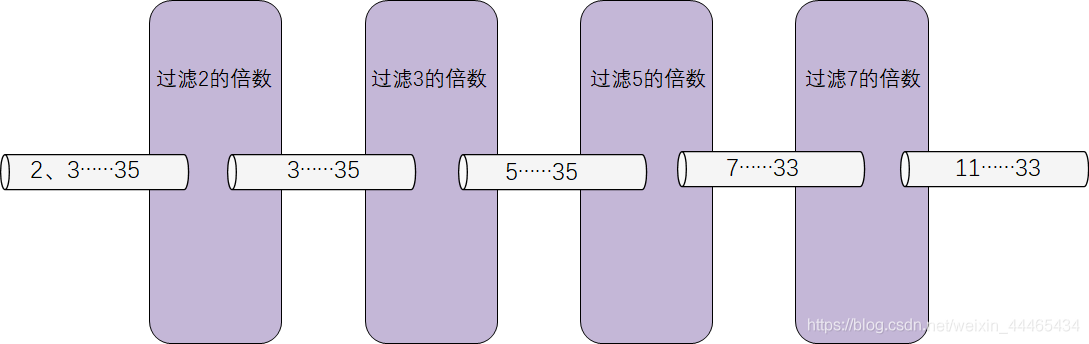
图片来源:[1] [2] 这是我见过的最奇怪的素数筛了,但其实还是很符合 “筛” 的定义的。每个进程就是一种特定的筛子,会筛掉一个质数的倍数,然后经过很多层“筛子”,我们就能得到最终的素数。注意,传给下一个进程的第一个数字一定是质数,因为该数字不能被任何一个比它小的数字(素数)整除(能被整除就在前面筛掉了)。
需要注意的一点是 fork() 之后,子进程会从 fork() 的下一行开始执行,毕竟 fork() 会把父进程的所有状态拷贝过来,包括 pc 寄存器。(其实是常识,没啥好注意的,只是我之前不知道,然后搞出了很傻逼的错误 )。
还有一点是用完了一个管道需要即时关闭,因为 xv6 的资源有限,一直不 close() 可能会让程序崩溃。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int main (int argc, char * argv[]) int pp[2 ]; pipe (pp); int pid; pid = fork(); if (pid == 0 ) { close (pp[SND]); child_proc (pp); } else { int init_num[MAX_P]; int idx = 0 ; for (int i = 2 ; i <= MAX_P; i++){ init_num[idx++] = i; } close (pp[REC]); send_to_next (pp[SND], init_num, idx); close (pp[SND]); wait (0 ); } exit (0 ); }
首先,在主函数的父进程中,我们需要先创建从 2 2 2 35 35 35 send_to_next() 函数,这个函数的作用就是把某个数组中的内容通过管道传给下一个进程。
其实现如下:
1 2 3 4 5 6 7 void send_to_next (int outpp, int msg[], int msg_len) for (int i = 0 ; i < msg_len; i++) { write (outpp, msg + i, sizeof (int )); } }
在主函数的子进程中,我们会调用 child_proc()。这个函数的唯一一个参数是管道的接收端,子进程会从这个管道接收没有被筛掉的数字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void child_proc (int pp[2 ]) int child_pp[2 ]; pipe (child_pp); int prime; int len = read (pp[REC], &prime, sizeof (int )); if (len == 0 ){ printf ("OK" ); exit (0 ); return ; } printf ("prime %d\n" , prime); int outlen; int * filtered = filter (prime, pp[REC], &outlen); close (pp[REC]); int pid = fork(); if (pid == 0 ){ close (child_pp[SND]); child_proc (child_pp); } else { close (child_pp[REC]); send_to_next (child_pp[SND], filtered, outlen); close (child_pp[SND]); wait (0 ); exit (0 ); } }
然后我们在这个 child_proc() 中会把接收到的第一个数字当作素数(原因如前面)。
然后用这个素数和 filter() 函数筛掉所有是这个素数倍数的数。filter() 的实现如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int * filter (int num, int inpp, int * outlen) (*outlen) = 0 ; int * out = (int *)malloc (MAX_P * sizeof (int )); int ret = 0 ; do { ret = read (inpp, out + (*outlen), sizeof (int )); if (out[(*outlen)] % num != 0 && ret > 0 ) { (*outlen)++; } } while (ret > 0 ); return out; }
筛掉当前素数的倍数后,就可以再创建一个进程,把剩下的数字传过去了。在子进程中,可以继续调用 child_proc():
1 2 3 4 if (pid == 0 ){ close (child_pp[SND]); child_proc (child_pp); }
需要注意我们调用 child_proc 时,传进去的管道不是原来那个 pp,是新创建的 child_pp。这样做是因为在一个进程中,我们既需要读读取上一个进程传进来的数字,也需要把过滤好的数字发到下一个进程中。
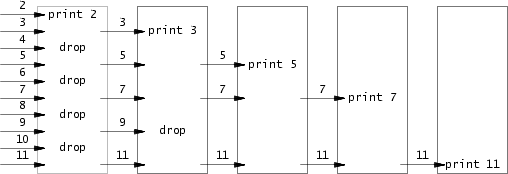
而管道是只能单向传输的,如果我们只使用一个管道。那么一个进程在接收上一个进程的数据时,不能 close() 管道的发送端,因为之后还要把过滤好的数据发到下一个进程上。
但 read() 一个管道时,如果不 close() 这个管道的发送端,这个 read() 是会阻塞的,也就是会卡在这里,等待新数据。因为系统不知道之后会不会有信息从发送端发过来。只有关闭了发送端才能表明传输已经结束,之后再也不会有新的数据从发送端传过来。
同时,因为最开始的时候,子进程和父进程的管道都是默认开启的,也就是说有两个进程打开了管道的发送端。那么如果只有一个进程关闭了发送端,我们去 read() 接收端时,还是会阻塞的,因为发送端并不是真正的关闭。
这样讲可能还是有点不清晰,下面这张图可以比较清楚的解释整个过程。
另外还有一点,在子进程执行 child_proc 时,父进程一定要调用 wait(),要不然可能会产生僵尸进程。
也就是父进程已经执行完而且调用 exit() 释完空间了,而子进程还在执行。
但是和直觉不太一样,子进程调用 exit() 释放资源呢后并没有完全从系统上消失,进程的描述符还存在在系统上,其唯一目的是给父进程提供信息。
所以我们需要父进程调用 wait() 来释放该进程最后剩余的进程标识符,slab缓存等,该调用会阻塞当前父进程,直到某个子进程退出[3]
像这样的僵尸进程会占用进程号,文件描述符等资源,所以会有危害。
除此之外,不加 wait() 也会导致你的程序通不过提供的单元测试 (./grade-lab-util)这也是为什么我会发现我程序有问题 。具体来说,在跑测试的时候,进程一直都不会结束,然后单元测试就会显示你超时。
在 shell 运行时也是这样,虽然已经输出了所有的质数,但 shell 一直不会输出 $。说明这个进程一直没有运行完毕。
不过我也不太清楚为什么僵尸进程会导致这样的现象,如果你清楚,可以在评论区说一下。
完整代码如下,参考了[1]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include "kernel/fd_types.h" #include "kernel/types.h" #include "user/user.h" #include "kernel/dbg_macros.h" const int MAX_P = 35 ;enum PIPE_END { REC = 0 , SND = 1 };void send_to_next (int outpp, int msg[], int msg_len) for (int i = 0 ; i < msg_len; i++) { write (outpp, msg + i, sizeof (int )); } } int * filter (int num, int inpp, int * outlen) (*outlen) = 0 ; int * out = (int *)malloc (MAX_P * sizeof (int )); int ret = 0 ; do { ret = read (inpp, out + (*outlen), sizeof (int )); if (out[(*outlen)] % num != 0 && ret > 0 ) { (*outlen)++; } } while (ret > 0 ); return out; } void child_proc (int pp[2 ]) int child_pp[2 ]; pipe (child_pp); int prime; int len = read (pp[REC], &prime, sizeof (int )); DEBUG ("len: %d\n" , len); if (len == 0 ){ printf ("OK" ); exit (0 ); return ; } printf ("prime %d\n" , prime); int outlen; int * filtered = filter (prime, pp[REC], &outlen); dbg_arr_i32 (filtered, 0 , outlen); DEBUG ("outlen: %d\n" , outlen); close (pp[REC]); int pid = fork(); if (pid == 0 ){ close (child_pp[SND]); child_proc (child_pp); } else { close (child_pp[REC]); send_to_next (child_pp[SND], filtered, outlen); close (child_pp[SND]); wait (0 ); exit (0 ); } } int main (int argc, char * argv[]) int pp[2 ]; pipe (pp); int pid; pid = fork(); if (pid == 0 ) { close (pp[SND]); child_proc (pp); } else { int init_num[MAX_P]; int idx = 0 ; for (int i = 2 ; i <= MAX_P; i++){ init_num[idx++] = i; } close (pp[REC]); send_to_next (pp[SND], init_num, idx); close (pp[SND]); wait (0 ); } exit (0 ); }
其中的 DEBUG 和 dbg_arr_i32 是一些调试用的函数或者宏,是我自己加在 kernel/dbg_macros.h 里面的,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #pragma once #include "kernel/fd_types.h" #if (!defined FPRINTF) #define fprintf(_stream, _fmt, ...) printf(_fmt, ##__VA_ARGS__) #endif #ifdef FDEBUG #define try(_expr, _act) \ { \ if ((_expr) < 0) { \ fprintf(STDERR, "try: %s failed, at line %d, file %s\n" , #_expr, \ __LINE__, __FILE__); \ _act; \ } \ } #else #define try(_expr, _act) #endif #ifdef FDEBUG #define DEBUG(fmt, ...) fprintf(STDERR, fmt, ##__VA_ARGS__) #else #define DEBUG(fmt, ...) #endif void dbg_arr_i32 (int arr[], int st, int ed) #ifdef FDEBUG for (int i = st; i <= ed; i++) { DEBUG ("%d " , arr[i]); } DEBUG ("\n" ); #endif }
find
这个可以参考 ls 的实现:
其实就是一个 dfs,如果检测到当前的路径是一个文件夹,那儿就 dfs 这个文件夹下的每一个文件/文件夹。
要获取文件夹里面放的东西,可以直接去 read() 这个文件夹。然后 read() 出来的是一个 dirent 结构体。
这个结构体的定义如下:
1 2 3 4 struct dirent { ushort inum; char name[DIRSIZ]; };
其中里面的 inum 是文件节点,跟文件描述符不太一样,有多个文件描述符可以指向一个文件,但是每个文件的 inum 是唯一的。
注意在文件夹中还需要跳过 . 和 .. 这两个文件,要不然就死循环了。
通过这个 dirent 结构体,我们可以直接把 name 加到当前的路径后面,然后把这个新的路径传入,继续递归。
其实这个程序需要的功能和 ls 不同,所以其实还可以再简化一下。
在 ls 中,因为不是递归实现的,所以对于最开始的文件节点需要调用 fstat() 来判断是文件夹还是文件。然后如果是文件夹,再调用 stat() 来输出该文件夹内每个文件节点的信息。
stat() 和 fstat() 都是用来获取文件节点信息的,唯一的不同是,fstat() 接收的是这个文件的标识符,而 stat() 则接收路径。
但是在 find 中,因为是递归的,所以只需要调用一个 fstat() 就够了(不用 stat())是因为我们已经通过 open() 获得了标识符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #include "kernel/fd_types.h" #include "kernel/types.h" #include "kernel/fs.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/dbg_macros.h" const int BUF_SIZ = 512 ;char * get_fname_from_path (char path[]) char * ptr = path + strlen (path); for (; ptr >= path && *ptr != '/' ; ptr--) { } return ++ptr; } void dfs_find (char * cur_path, char * name) int cur_fd; char nexdir_buf[BUF_SIZ]; struct stat cur_stat; struct dirent nex_dir; try (cur_fd = open (cur_path, 0 ), return ); try (fstat (cur_fd, &cur_stat), return ); if (cur_stat.type == T_FILE) { if (strcmp (get_fname_from_path (cur_path), name) == 0 ) { printf ("%s\n" , cur_path); } } else if (cur_stat.type == T_DIR) { strcpy (nexdir_buf, cur_path); char * path_end = nexdir_buf + strlen (nexdir_buf); *(path_end) = '/' ; path_end++; while (read (cur_fd, &nex_dir, sizeof (struct dirent)) == sizeof (struct dirent)) { if (nex_dir.inum == 0 ) continue ; if (strcmp ("." , nex_dir.name) == 0 || strcmp (".." , nex_dir.name) == 0 ){ DEBUG (". or ..\n" ); continue ; } memmove (path_end, nex_dir.name, DIRSIZ); path_end[DIRSIZ] = '\0' ; try (stat (nexdir_buf, &cur_stat), continue ); dfs_find (nexdir_buf, name); } } close (cur_fd); } int main (int argc, char * argv[]) if (argc != 3 ) { fprintf (STDERR, "usage: find <directory> <file name>" ); exit (114 ); } dfs_find (argv[1 ], argv[2 ]); exit (0 ); }
xargs
最开始搞了好久都没搞懂这东西是干啥的。其实就是因为把标准输入的数据传到一个命令中。xargs 的第一个参数是另一个命令的名字。然后我们需要把之后所有的参数,和从标准输入输进来的数据,当作那个命令的参数,去执行那个命令。
有这个 xargs 其实是因为很多命令不支持读取管道的输入作为参数,因为 shell 里的管道会把上一个命令的标准输出输出到下一个命令的标准输入上,所以我们需要从标准输入读出这些东西,然后作为参数给另一个命令执行。
比如 echo hello too | xargs echo bye 。管道会往 xargs 的标准输入输入 “hello” 和 “too” 两个字符串,xargs 就需要读取这两个字符串,然后和 “bye” 这个参数一起,作为执行第二个 echo 的参数,去执行 echo。
所以我们首先需要通过换行符和空格来判断不同的参数,然后把它们分割开来,存进入另一个字符数组(std_args)。
然后再开一个新的字符数组,作为 exec() 时传进去作为参数的字符数组(arg2pass)。首先需要在 arg2pass 中放入命令的名字(也就是 argv[1])然后再放入剩余的 argv。最后再把 std_args 加进来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 #include "kernel/types.h" #include "user/user.h" #include "kernel/fd_types.h" #include "kernel/param.h" #include "kernel/dbg_macros.h" const char * DEFAULT_CMD = "echo" ;#define MX_ARG_CNT 32 #define MX_ARG_LEN 32 char cut_str_by (char * src, char * dst, int * srcpos, char * signs) for (int i = *srcpos; src[i] != '\0' ; i++) { for (int s = 0 ; signs[s] != '\0' ; s++) { if (src[i] == signs[s]) { src[i] = '\0' ; strcpy (dst, src + *srcpos); *srcpos = i + 1 ; return 1 ; } } } return 0 ; }; char std_args[MX_ARG_CNT][MX_ARG_LEN];int main (int argc, char * argv[]) char * cmd; if (argc == 1 ) { cmd = DEFAULT_CMD; } else { cmd = argv[1 ]; } int argcnt = 0 ; char buf[MX_ARG_LEN * MX_ARG_CNT]; int curlen = 0 ; int lst_pos = 0 ; try (read (STDIN, buf, sizeof (buf)), exit (1145 )); memset (std_args, 0 , sizeof (std_args)); while (cut_str_by (buf, std_args[argcnt], &lst_pos, "\n " )) { while (buf[lst_pos] == '\n' || buf[lst_pos] == ' ' ) { lst_pos++; } argcnt++; } char * arg2pass[MX_ARG_CNT]; int lst = 0 ; arg2pass[lst++] = cmd; for (int i = 2 ; i < argc; i++) { arg2pass[lst++] = argv[i]; } for (int i = 0 ; i < argcnt; i++) { arg2pass[lst++] = std_args[i]; } exec (cmd, arg2pass); exit (0 ); }
总结
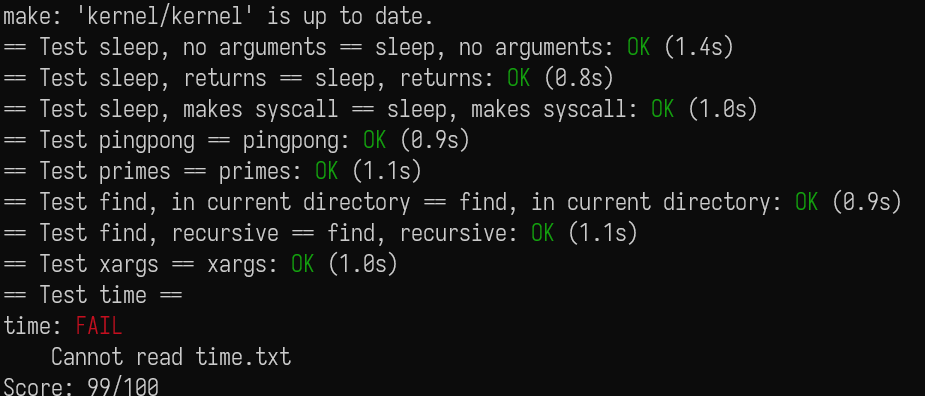
先来张 AC 的照片,也祝在做这个 lab 的人尽快 AC。
感觉大部分还是不难想的,主要是调试浪费了很多时间导致我的速度奇慢无比。因为常年使用 C++ 的 stl,现在对 C 都不是特别熟悉了,特别是调试 cstring 时浪费了很多时间。所以之后还是应该练习一下调试的技巧,以及 C 语言。



![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)