[MIT 6.s081] Xv6 操作系统学习笔记
书的链接(中文翻译版):https://github.com/duguosheng/6.S081-All-in-one
第零章
这章大部分的内容还是能够看懂的,但是在管道的示例程序上卡了很久。最后终于搞懂了,这里把我的理解写一下:
1 | int p[2];//p[0] 储存管道接收端的文件描述符,p[1] 为管道发送端的描述符 |
首先需要注意的是父子进程的文件描述符是共享的,比如这里的 pipe() 函数,看似是运行子进程后又打开了一个管道,但是因为打开的文件描述符是共享的,实际父进程和子进程中的 p[0] 和 p[1] 指向的是一个文件,方便了进程之间的交流。
除了文件之外,根据《UNIX环境高级编程》,还有以下的资源也是父子进程共享的( 虽然我基本都不懂 )。

而不同的地方则是:

对于这段程序中的父进程,通过 pipe() 拿到管道的文件标识符后,会往 p[1],也就是管道的发送端,写入 hello world。然后关闭管道的两端。比较容易理解。
对于子进程,会先 close(0),这里的 是代表 stdin 的标识符,然后呢用 dup(p[0]) 把 p[0] 这个标识符复制到另一个标识符上。
比如我们写 x = dup(y),那么 x 和 y 就会指向相同的文件。可是这里调用 dup() 时并没有接收返回值,那我们如何知道会被复制到哪个标识符上呢?
其实 dup() 会在所有标识符中从小到大找到第一被关闭的表示符,在子进程的程序中,我们先关闭了 stdin,也就是 ,那么调用这个 dup() 自然会把 p[0] 重定向到 stdin 上,也就是我们读取 stdin 相当于读取了 p[0]。
接下来在子进程中,调用了 exec() 去执行 wc 命令,这个命令会统计文件的字数。可以发现,我们传给这个命令的参数的 argv[1] = 0。我们希望让 wc 统计标准输入的字数。
需要注意的是调用 exec() 之后,系统会直接把新的程序写进这个进程,也就是说进程直接变成了 exec() 的程序。所以调用 exec() 之后是永远不会返回的。如果希望当前进程不被取代,可以先 fork(),然后在子进程中 exec()。
但是因为前面的 dup(), 现在的标准输入已经被重定向到了 p[0],那么我们实际统计的就是从管道 p[1] 传进来的数据,也就是 write(p[1], "hello world\n", 12) 里的 hello world。
还有一点我最初也感到很奇怪。既然父子进程是共享文件标识符的,那么 p[0] 和 p[1] 被关闭两次,不会出问题吗?
于是我就找到了这篇文章,终于搞懂了。
close()函数关闭文件时,并不是在任何情况下都直接关闭文件,而是找出file结构体中f_count成员,执行自减操作;直到f_count为0,才是真正的关闭文件。这就是著名的技术——引用计数。
页表
强烈推荐一篇文章:https://zhuanlan.zhihu.com/p/351646541 非常详细的介绍了 xv6 页表相关的知识。下面的文章也大量参考了这篇文章。
页表的简介
页表是一种特殊的数据结构,用于实现操作系统中的内存虚拟化。页表储存了一个从虚拟地址到物理地址的映射。对于每个进程,操作系统都会维护一个页表,在每个进程中,也只能通过这个页表来访问物理内存,这样每个进程都在表面上拥有了一整台机器的资源。并且,一个进程的内存发生了泄露,也不会影响到另一个进程。
从虚拟地址到物理地址的转换是通过 CPU 中的内存管理单元完成的。如下图:
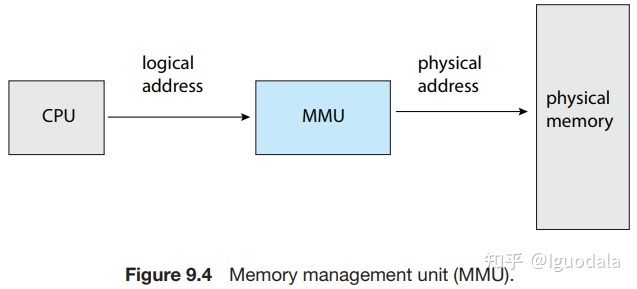
除了增强进程间的隔离性,页表和虚拟地址的作用就是更高效的利用计算机的内存。在实际中,我们是很难在内存中找到一大段空间的,这就会导致一种情况:当程序申请一段内存时,尽管总的空闲内存超过用户需要的内存,但是每段连续的内存都不能满足。因为随着时间推移,程序和数据被不断的移出和加载进内存中,内存中的碎片也越来越多。而页表把内存划分成了很多块,这样我们就可以把一段连续的虚拟内存映射到间断的物理内存上,从而更高效的利用空间。
最后,使用页表和虚拟内存还可以实现很多别的骚操作。如同时把一个物理地址映射到两个虚拟地址上。
risc-v 的页表实现
最简单的页表实现就是一个类似数组的东西,记录着虚拟内存到每块内存的映射(也就是页帧,xv6 上一个页帧为 4KB)。
但是,这样的线性数组本身就需要很大的空间储存。我感觉现在大部分的个人电脑都有 8GB 的内存,那接下来可以算一下 8GB 的内存会需要多少空间储存页表。
首先,如果一个页帧为 4KB,那么 8GB 的内存中一共有 个页帧。对于每一个页帧,我们都需要有一个从虚拟地址的映射。假设我们使用的是 64 位的机器(8GB 的话只可能是 64 位的),那么就需要 8 个字节来储存一个地址。所以我们共需要 的空间储存页表。
如果一个 8GB 的机器就使用这么多的空间储存页表,也没什么。关键的问题是,对于系统中的每一个进程,我们都需要开一个新的页表来保存这个进程专属虚拟地址空间(并且内核态和用户态程序单独开)。那如果有 50 个进程正在运行,我们就需要 的内存来储存页表,这显然是不可接受的。
为了解决这个问题 risc-v 和几乎所有其他的现代处理器都使用了多级页表的方式。
具体来说,risc-v 使用了三级页表,可以理解为一个三层的树。树的根节点有 512 个子节点,这 512 个子节点是必须有的,剩下的两层子节点可以有最多 512 子节点(不是必须)。
这些子节点的正式名称是页表条目PTE(Page Table Entry)。每个 PTE 为 54 位(risc-v 能处理 64 位的虚拟地址,但是物理内存最多为 56 位数)其中,44 位为物理页帧号,用于索引下一页页表,10 位为一些标志位,用来记录一些关于当前 PTE 指向的 PTE 或内存的信息。
这就是为什么前面说,剩下的两层子节点不一定有 512 个子节点,并且因此,可以节省一定空间。因为我们可以利用 PTE 中的标志位来判断,当前这个 PTE 指向的下一个页表是否存在,如果说标志位指示其不存在,那就完全不需要储存这个 PTE 指向的页表了。而在单级页表中,就算我们可以用标志位指示这个页帧不存在,也必须储存对应的 PTE。
同时,多级页表和 PTE 中的标志位还可以让我们把一些页表交换到硬盘中,需要的时候再取出来,因此更大程度的节省空间。
那么拿到了一个虚拟地址之后,具体是如何转换成物理地址的呢。
我们先要了解 xv6 中使用的虚拟地址是什么样的,(可能因为方便教学?)xv6 中的虚拟地址只有低 39 位数是在使用的,剩下的 25 位都是保留位。
CPU 中的 satp 寄存器会指向当前页表的根页表,我们的要转换的虚拟地址就是基于这个 satp 指向的页表。
然后如下图所描绘:
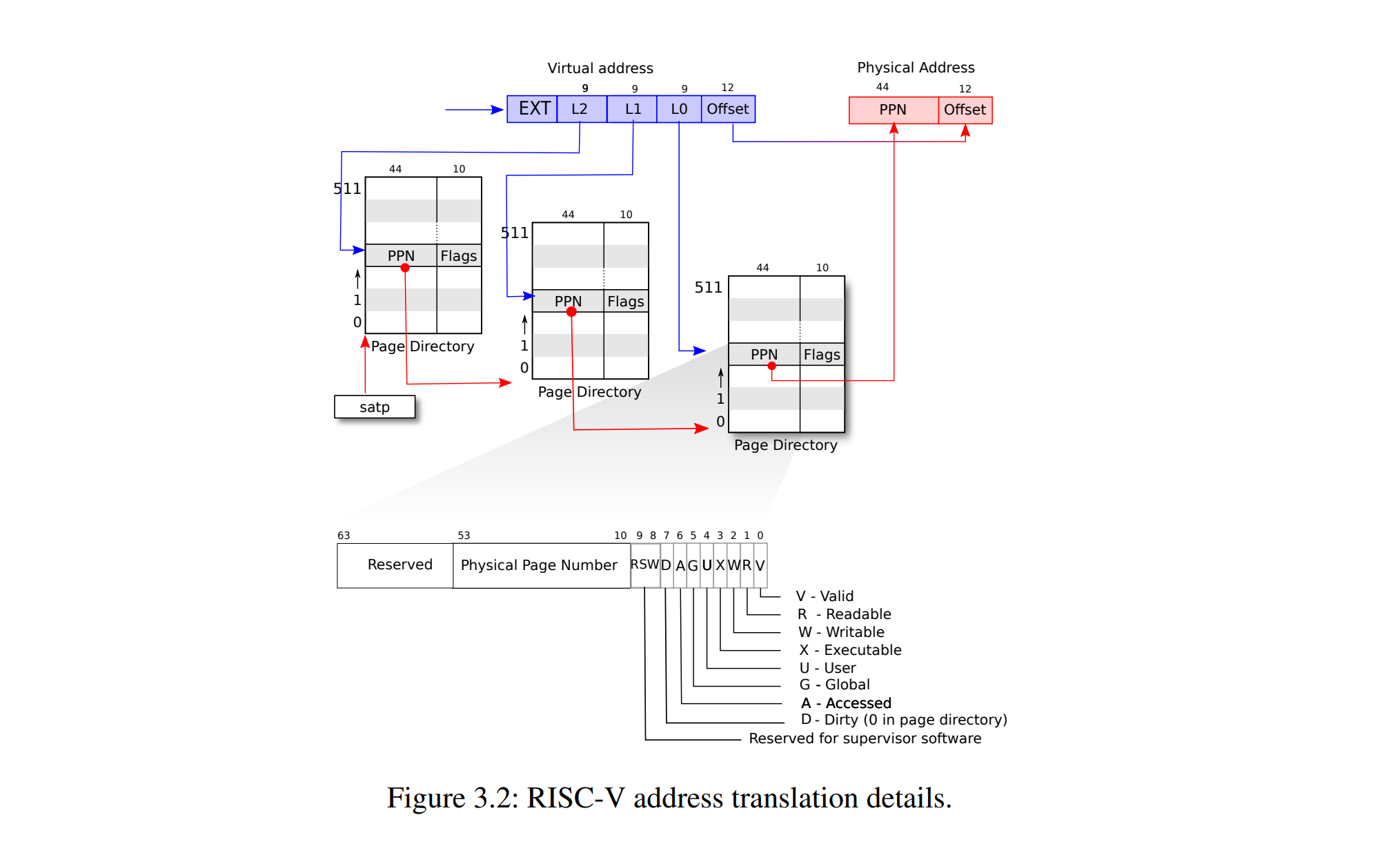
虚拟地址的前 9 位指定了应该选取根页表中的哪个 PTE,这个 PTE 储存着一个物理地址,根据这个地址就能找到下一级 PTE。因为总共有三级页表,所以这个过程需要重复三次。相应的,对于每一级页表,虚拟地址中有 位来储存应该选取哪一个 PTE。而虚拟地址剩下的 12 位指示了在页帧中的偏移量()。
上图的下半部分还展示了 PTE 中的各种标志位,如:
- V (valid) 指示该 PTE 指向的页表(或页帧)存在
- R (readable) 指示是否可读
- W (writable) 指示是否可写
- X (exacutable) 指示是否可以把内存中的数据当成指令执行
- ……
xv6 内核态的虚拟内存布局
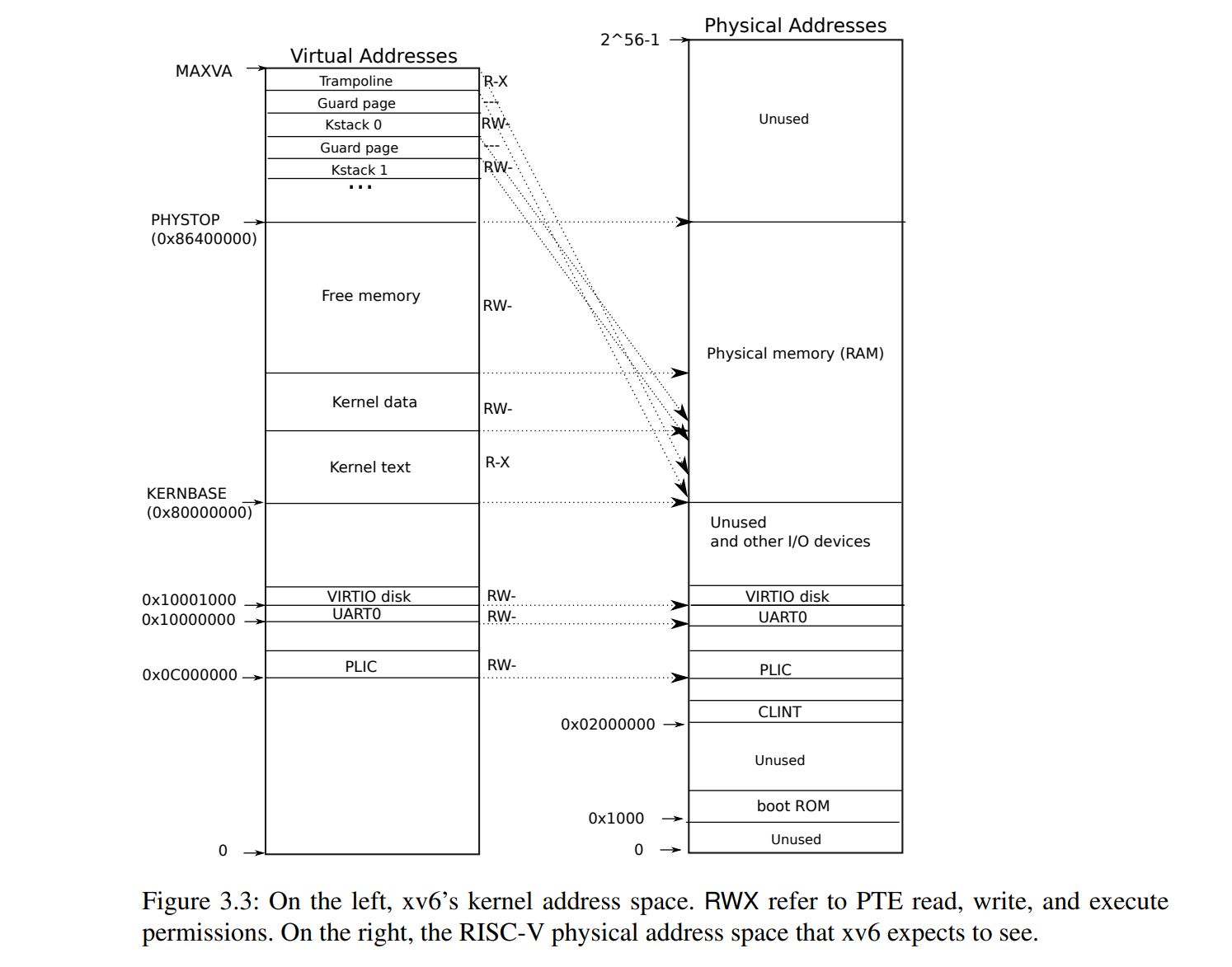
在 qemu 中,RAM 的内存是从 0x80000000 (KERNBASE) 开始的,在这个地址下面的都是一些 IO 设备,比如网卡或是一些中断控制器,读取和写入这些特殊的内存可以实现和 IO 设备通信,RAM 的截止位置为 0x86400000 (PHYSTOP) ,共计 128 MB。
在内核中,除了两个特殊的页帧外,所有的虚拟地址都被直接的映射到物理地址中。这样就允许了内核更方便的操作物理内存。同时,因为这样的直接映射,内核还可以模拟 MMU 的行为,在页表不同的情况下读取用户态的数据( walk 函数,之后会讲到)。
页表中没有直接映射的两部分为 trampoline(蹦床) 和内核栈。
trampoline 被映射到了虚拟地址的顶端,在用户态中,这个相同的物理地址也被映射到了顶端。(至于为啥这么搞,应该会在 trap 那章有解答,我现在还不知道)
而内核栈在虚拟地址的顶端和中间部分都被映射了一遍(中间部分是直接映射)。这是因为 guard page 的设计。
guard page(可以翻译为保护页?)是一个为了防止栈溢出的设计,其 PTE 中的 V 标志位并没有被设置,这样我们访问保护页时,就会发生 page fault。
可以看到内核栈是被夹在保护页中间的,这样发生栈溢出,并且访问到这些保护页时,就会报错,而不会访问到内核栈不该访问的地方。
为了节省空间,这些保护页其实没有被映射到任何物理地址上,这也是使用虚拟内存才能实现的灵活操作,你可以把一个物理地址映射到多个虚拟地址,也可以不把一个虚拟地址映射到任何物理地址上。
xv6 用户态的虚拟内存布局
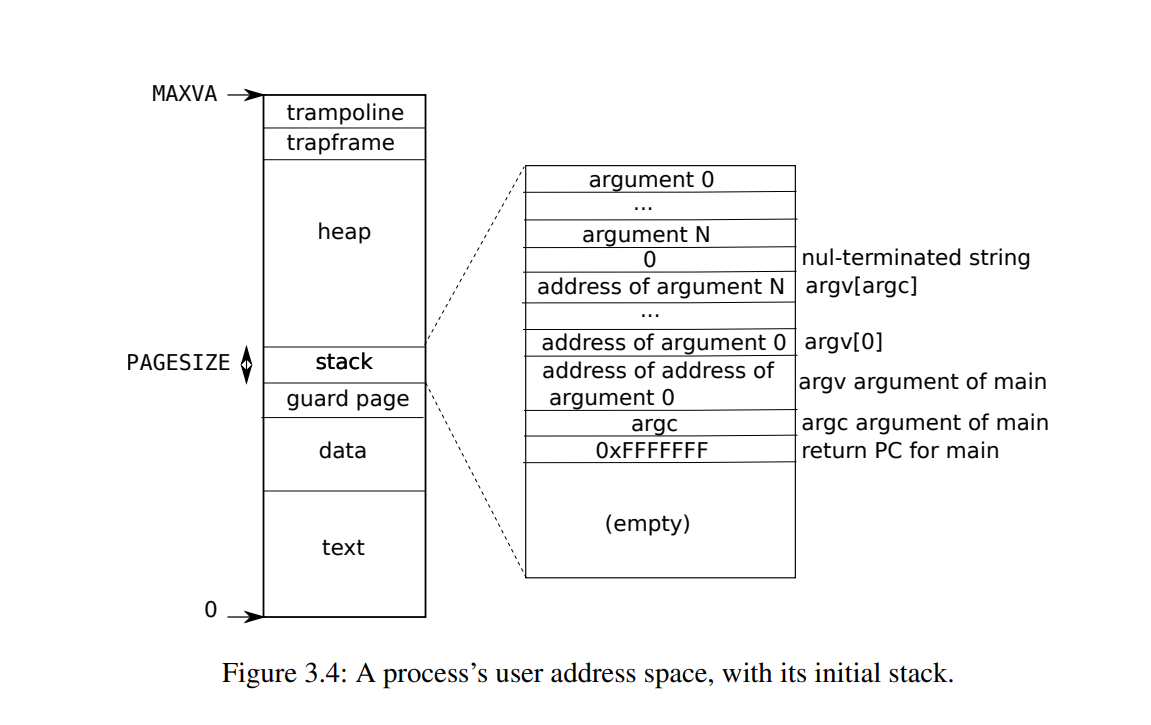
用户态的虚拟内存布局就没什么特别了,除了最上面的 trampoline,如前面所说,这一页也被映射到了内核的虚拟内存中。
而 trampoline 下面的 trapframe 是用来在系统调用和发生 trap 时,保存各个寄存器的状态的。
一些代码
鸽
陷入
陷入机制的作用
在正常的情况下,我们写一个程序,那么这个程序运行起来大概是一个 “线性” 的过程,也就是程序里的内容是一条接着一条的运行下去的。
但在某些特殊情况下,这样“线性”的运行过程会被打破。比如我们熟悉的系统调用,就会暂停用户态程序的状态,跳转到内核态执行一些服务,然后再跳回用户态。
这样在用户态和内核态之间切换,去处理特殊性事件的过程,在 xv6 中称为陷入(trap)。
至于为啥叫陷入,我觉得下面这张图[1]挺形象的,就像是“陷入”到一个坑里又出来了:
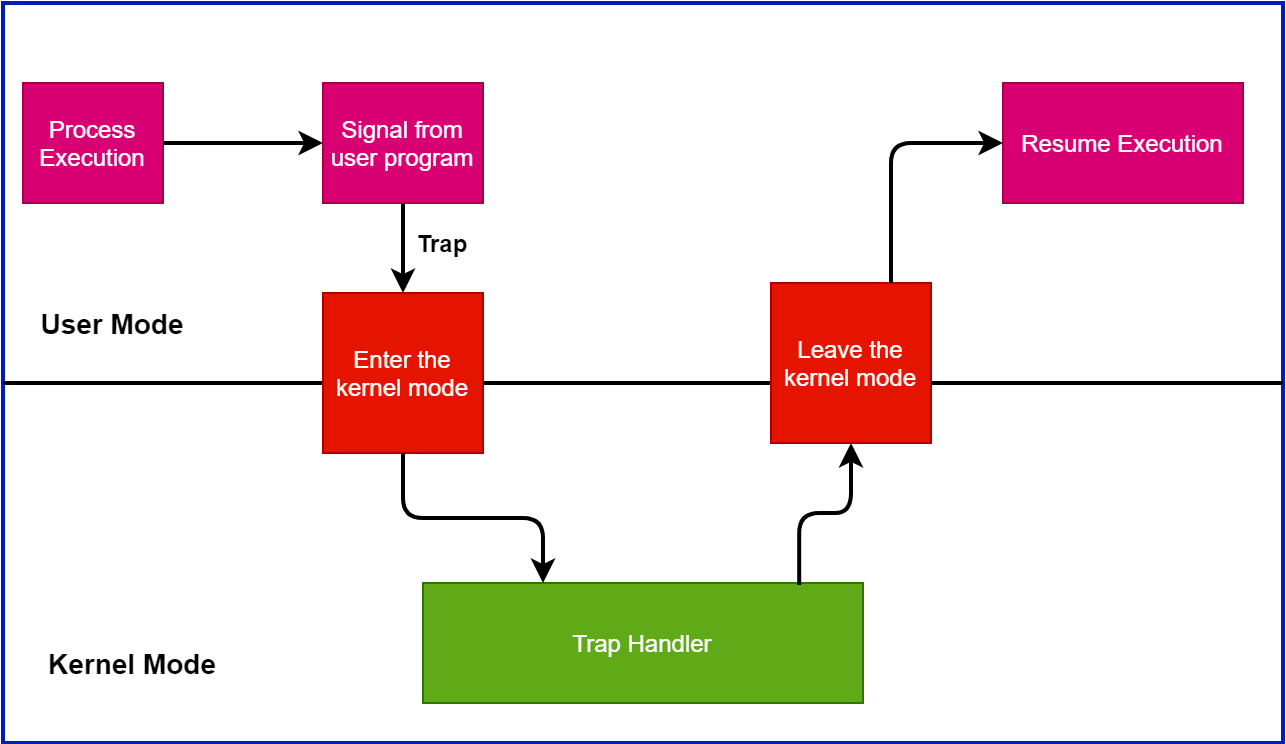
通常有以下几种情况会发生陷入:
- 系统调用
- 异常,如除以 0
- 设备中断,比如计时器中断
首先介绍一下陷入机制中会用到的一些寄存器:
- stvec (Supervisor trap handler base address,监管者陷入处理器基址?(
乱翻译的)): 这个寄存器存放了中断处理程序的地址,也就是,发生陷入时,会跳转到这个寄存器里的地址,然后进行下一步的处理。 - sepc (Supervisor exception program counter,监管者异常程序计数器):因为发生了陷入,即将跳入中断处理程序,所以我们需要向条用函数时,把原来的 PC 存起来,之后可以恢复现场。所以这个 sepc 就储存了原本(如果没有发生陷入)要执行的下一条指令。
- scause (Supervisor trap cause,监管者陷入原因):储存了引发陷入的原因,可能是系统调用,异常,或是中断。
- sscratch (Scratch register for supervisor trap handler):这个寄存器一般用于储存 trapframe 的位置。
- sstatus (Supervisor status register):这个寄存器里面存的是一些标志位,具体如下:
 其中比较重要的有 SIE (我猜是 Supervisor interrupt enable),和 SPP (我猜是 Supervisor previous privilege level)。SIE 位表明现在是否处理中断,如果这位为 0,那就不处理,因为有时候正在处理陷入,这个时候肯定不能再处理中断了。SPP 储存是从用户还是从内核态陷入的。
其中比较重要的有 SIE (我猜是 Supervisor interrupt enable),和 SPP (我猜是 Supervisor previous privilege level)。SIE 位表明现在是否处理中断,如果这位为 0,那就不处理,因为有时候正在处理陷入,这个时候肯定不能再处理中断了。SPP 储存是从用户还是从内核态陷入的。 - satp (Supervisor address translation and protection):这个东西之前第二章的部分提到过,储存的是当前的根页表。
从用户态陷入
下面会以一个系统调用的过程为例去讲解 xv6 的陷入机制。
在 lab2 的试验记录中,提到了会通过 ecall 指令从用户态切换到内核态,但是并没有详细解释这中间发生了什么(其实是我不知道),学过 trap 这章的内容,就可以明白了。
ecall 指令会干以下的事情[2]:
- 如果是设备中断产生的 (这个其实不是 ecall,但是也放一起讲了),并且 SIE 位是 0,(代表不处理中断)那么就不做任何操作。
- 清除 SIE 以禁用中断(因为 ecall 会引发陷入,我们不能同时处理两个陷入)
- 储存当前模式至 sstatus 的 SPP 位。
- 设置当前模式为监管者模式。
- 复制 pc 的值到 sepc,用于之后的恢复现场。
- 复制 stvec(储存中断处理程序的地址)到 pc,这样会自动跳转到中断处理程序。
- 设置 scause 反应陷入的原因。
前面说 ecall 之后会跳到 stvec 指向的位置,在 xv6 中的用户态,这个位置指向的是 kernel/trampoline.S 中的 uservec。在内核态时,指向的是 kernel/kernelvec.S。
更具体的,这个 kernelvec 最早是在 main 函数中被设置的,也就是 main 的 trapinithart()。
这个函数干了以下的事情:
1 | // set up to take exceptions and traps while in the kernel. |
也就是把 kernelvec 的地址写入 stvec。
不过我们现在的例子是从用户态陷入,所以先放一下 kernel/trampoline.S 中 uservec 的代码:
uservec
1 | uservec: |
其中有几个比较重要的地方,第一个是
1 | csrrw a0, sscratch, a0 |
这行代码交换了 a0 和 sscratch 的值,也就是从这句话开始,a0 就指向了 trapframe。我们不能直接使用 sscratch,而是交换后使用的原因是:sscratch 是特权级的寄存器,而 sd 和 ld 等命令只能操作通用寄存器,特权寄存器一般是 csr 开头的指令操作(这块我也不太懂)。
接下来,我们通过 sd ra, 40(a0) 这样的命令,把寄存器中的值复制到内存的 trapframe 中。在内核态的 c 代码中,我们可以通过 trapframe 结构体访问这个 trapframe:
1 | struct trapframe { |
其中,sd 的意思是 store,也就是储存 ra 的值到 a0 寄存器中的地址偏移 40 个字节的位置。
接下来,我们除了 a0 以外的所有寄存器都被复制了一遍,所以要再来复制一遍 a0:
1 | # save the user a0 in p->trapframe->a0 |
注意因为前面交换过,现在这个 sscratch 储存着用户态 a0 的值,然后这个寄存器又和 t0 交换了下,t0 就成了用户态的 a0。因此 sd t0, 112(a0) 就保存了 用户态 a0 的值。
接下来,我们需要把处理器的环境完全的切换到内核中。因为我们之前用的是用户态的页表以及栈指针等,所以要更新相关寄存器的值。
然后就有了如下的代码,其中 ld 命令表示 load,及从内存中复制值到寄存器中:
1 | # restore kernel stack pointer from p->trapframe->kernel_sp |
这里有个比较有意思的点,就是 trampoline 页(uservec 就放在 trampoline 页)在内核态和用户态的虚拟地址都是一样的,也就是同一个物理地址被映射了两次(页表部分有讲)。这样的设计允许使用 csrw satp, t1 命令更换页表后继续执行 uservec 的程序,不得不说还是很巧妙的。
trapframe 中的这些值(及内核态的根页表,内核态的栈指针等)其实是内核态第一次进入用户态时存下来的。
可以在 kernel/trap.c 的 usertrapret() 函数中找到:
1 | // set up trapframe values that uservec will need when |
然后就到了 uservec 的最后一条代码:
1 | jr t0 |
也就是跳转到 t0 寄存器的位置。注意前面的这句话:
1 | # load the address of usertrap(), p->trapframe->kernel_trap |
我们把 usertrap 函数的值加载到了 t0 中,那么 jr 之后就会跳转到 usertrap 函数中。
总结一下,uservec 一共干了下面这些事情:
- 保存线程(32 个通用寄存器)
- 恢复内核运行环境(内核页表,栈指针等)
- 跳转到 usertrap 执行
usertrap
接下来,就到了 usertrap,代码如下:
1 | void |
首先用一下代码判断中断是用户态来的还是从内核态来的:
1 | if((r_sstatus() & SSTATUS_SPP) != 0) |
如果是内核态来的,就……就……处理不了了,直接来个 panic 摆烂了。
如果是用户态的话,那会先用如下代码把 stvec 改成 kernelvec:
1 | w_stvec((uint64)kernelvec); |
因为万一在内核中发生中断,处理逻辑是不一样的,所以不能用 uservec 的程序。
1 | p->trapframe->epc = r_sepc(); |
注意我们这里把 sepc 储存起来是因为,在内核态处理时,可能会切换到另一个进程,而这个进程也可能会去调用系统调用。这个时候 sepc 寄存器的值会被覆盖,那么我们现在把他存起来了,就算中途去处理另一个进程的系统调用,回来的时候也没问题。
并且我们是在这些都保存好后,才去调用 intr_on() 打开中断的,这样只有保存好信息后在可能去在别的进程中执行中断。(打开中断时因为系统调用可能比较费时间,这段时间中,cpu 可以同时处理别的进程)
后面的话基本上就是按照产生陷入的原因,去做不同的处理。如,如果是因为系统调用产生的陷入,那么一定使用了 ecall 指令,这时候我们就希望系统调用执行好了后在用户态执行的是 ecall 的下一条指令,所以要把 sepc 改成 sepc + 4。
如果是设备产生的中断,那会在 devintr() 函数中相应的处理逻辑。
如果产生了异常,那就直接把那个发生陷入的进程 kill 了。
所以这个 usertrap 函数大概干了如下的事情:
- 判断产生陷入的原因是系统调用/中断,还是异常,并且做相应的处理
- 更改 stvec 的值,以应对内核中发生的中断,更改(可能)和储存 sepc 的值(原因见前文)。
这段代码的最后一行调用了 usertrapret() 这个函数,做了一些返回前的工作。
usertrapret
代码如下:
1 | void |
这个函数中,我们会先关掉中断,然后把 stvec 从 kernelvec 改回 uservec。
接下来,为了之后用户态发生陷入时,能成功恢复内核态的一些上下文,会把一些寄存器的值存入 trapframe(见 uservec 的部分,uservec 会用到这些):
1 | p->trapframe->kernel_satp = r_satp(); // kernel page table |
然后我们又重置了 sepc,因为从陷入返回时会根据这个寄存器的内容来重置 pc,以执行用户态陷入之后的程序。
函数的最后两行:
1 | // jump to trampoline.S at the top of memory, which |
用这个骚操作跳到了 trampoline 页中的另一个函数 —— userret。
总结一下,usertrapret 干了下面的事情:
- 在 trapframe 中复制能恢复内核上下文的一些数据,如内核页表,内核的栈指针,以及内核中的陷入处理程序。
- 恢复 stvec 和 sepc 的值。
- 调用 usertrapret
其实我感觉 stvec 和 sepc 这两个东西没必要在 usertrapret 中储存,它们本质也是恢复 trapframe 的数据。
userret
基本上就是 uservec 的“反函数”,代码如下:
要注意这个函数是有两个参数的,即 trapframe 的地址和用户态页表的地址,按照 xv6 的函数调用规则,分别放在 a0 和 a1 寄存器。
1 | userret: |
所以这个函数基本就是把所有的通用寄存器从 trapframe 里恢复了一遍,并且切换了页表,最后使用了 sret 指令。
注意这个 sret 指令,也和 ecall 指令一样,能同时做很多事情,具体的,有以下几个:
- 换回用户模式
- sepc 寄存器的数值会被拷贝到 pc 寄存器
- 打开中断
然后就可以愉快的继续执行用户态的程序了。
总结一下, userret 做了一下事情:
- 恢复 32 个通用寄存器的值
- 恢复页表
- 调用 sret
中断
待更新(鸽)
线程调度
简介
现代操作系统通常会提供多线程的功能,也就是在表面上同时的执行多个任务。实现多线程主要有以下的原因[3]:
- 有时我们会需要在计算机上同步的执行多个任务。比如,现代操作系统会允许多个用户同时登陆计算机,并运行各自的进程。
- 多线程可以优化代码结构,或者让程序变得更易于理解和维护。lab1 中的 prime 就是一个使用多线程优化程序结构的例子。
- 多线程结构能更好的利用现代的多核处理器。
在实践中,我们通常会按照经过的时间让处理器运行不同的任务来实现多线程,或者说让处理器快速的在不同线程中切换以实现同步运行的假象。
实现多线程有上面列举的好处,也有很多困难,比如[3]:
- 如何实现线程间的切换?
- 实现线程间切换时,我们需要保存和恢复线程的状态,那么就需要决定,具体要保存哪些信息?
- 对于某些计算密集型线程,可能很久都不会结束计算并自愿的让出处理器,那我们如何夺回对处理器的控制?
下面会以一个具体的从一个用户进程切换到另一个用户进程的例子,来描述 xv6 中对多线程的实现。
下面这张来自 xv6 书中的图就大致的解释了 xv6 中进程切换的过程:
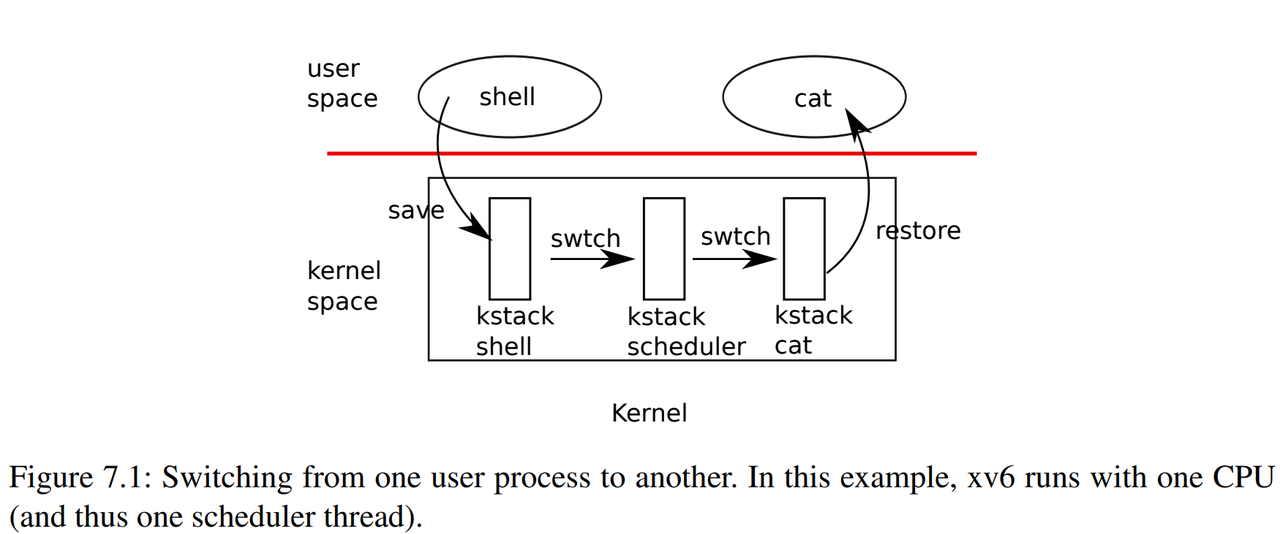
代码
中断
大部分进程切换的开始其实是一个硬件引发的计时器中断。在 xv6 中,我们会设置 rsicv 的处理器来产生计时器中断,也就是,每过一段时间,都会产生一个中断来提醒我们某个进程已经占用处理器够多的时间了,需要切换进程。
如果产生这个中断的时候,我们正在跑用户态的程序(也就是上图展示的),那么处理这个中断的函数就是 kernel/trap.c 中的 usertrap():
1 | …… |
如果我们发现产生中断的外部设备是计时器,就会调用下面的 yield() 函数:
1 | // Give up the CPU for one scheduling round. |
这个 yield() 除了给进程上锁和解锁,就调用了 sched()。
而 sched() 其实也是给 swtch() 套了层皮:
1 | // Switch to scheduler. Must hold only p->lock |
切换
函数中前面的一堆判断加 panic 其实都是一些合法性检查,我们先不用关注,主要看这里的 swtch() 函数。顺便提一嘴,这函数因为跟 c 语言关键重了,所以少了个 i(乐 。
swtch 函数是用汇编实现的,在 kernel/swtch.S 文件中,如下:
1 | # Context switch |
可以看到,这个函数其实是把一些当前的寄存器储存在了 old->context 里面。然后读取 new->context 里读取了数据,并用这些值给寄存器赋值。
这个函数的实际作用是切换内核线程的上下文,也就是如一开始那张图所示的,从 kstack shell 切换到 kstack scheduler 的线程。
看到这里,你可能会感到很奇怪,既然 swtch() 函数切换的是不同线程的上下文,那为啥没有像 trapframe 一样,保存所有 32 个通用寄存器的值,而只保存了 14 个呢?
这是因为 s0-s11 在 xv6 的函数调用规则中,都是由被调用者保存的。而 32 个通用寄存器中剩下的那些,都是由调用者保存的。
也就是说,这些剩下的寄存器都是可以通过 sp 加上一些偏移量从栈中恢复的,我们也自然没有理由去保存它们。
关于具体的调用者和被调用者保存寄存器,可以参考下面 riscv 文档上截下来的图:
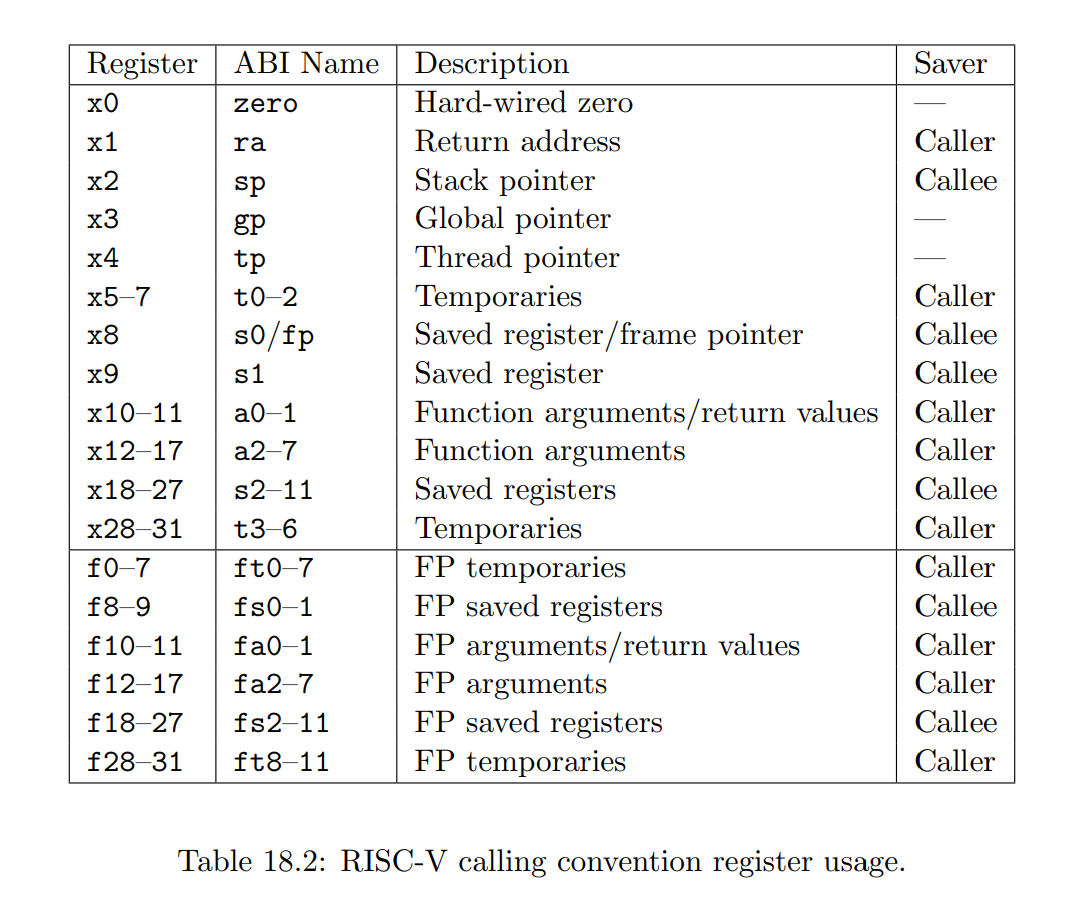
这里要特别注意的是储存和恢复的 ra 和 sp 寄存器。
其中 ra 寄存器表明了 swtch() 函数结束时会返回到哪个地址,而 sp 则表明了当前栈的位置。这意味着,在 swtch() 返回的时候,不会返回到 sched() 的最后一个语句,而是返回到 mycpu()->context.ra 指向的位置。
调度
而 mycpu()->context 中的 ra 指向的是 scheduler() 函数的一个位置(和上图演示的切换过程一样):
1 | // Per-CPU process scheduler. |
那为啥返回的是这里呢?我们可以看 kernel/main.c 的内容:
1 |
|
在初始化工作完成后,第一个执行的函数就是 scheduler()。那在 scheduler() 函数中,我们找到了一个 RUNNABLE 的进程,然后执行了 swtch(&c->context, &p->context);。
这个时候的 sp 寄存器和 ra 寄存器指向的自然是 scheduler() 函数,所以 mycpu()->context 中的 ra 也是 scheduler() 中 swtch() 后面的地址。
这个感觉就很奇妙,像是一个传送门和 “时光机”,相当于我们在某个地方调用了 swtch() 后,返回的是另一个地方很久(对计算机来说)之前调用 swtch() 的地方。或者说,这个函数的调用和返回是分离开的,我们调用的 swtch ,一定是通过另一个地方调用的 swtch 返回的[4]。
在 sched() 函数调用 swtch() 后,我们会从 scheduler() 函数调用 swtch() 的后面开始,继续执行 scheduler() 函数。这个函数的主要用处就是找到一个 RUNNABLE 的进程,然后执行 swtch()。
在 swtch() 之前,会先执行下面的操作:
1 | p->state = RUNNING; |
也就是把进程结构体的状态改成 RUNNING,以及把 mycpu() 的 proc 属性改成 p。
这样我们在切换进程后调用 myproc() 就能得知当前处理器正在执行的进程。如下:
1 | // Return the current struct proc *, or zero if none. |
其实就是返回了处理器上下文中的 proc 属性。
和前面讲的一样,swtch() 像是一个传送门,这个函数的调用和返回是分开的,调用后,会返回另一个地方之前调用 swtch() 的位置。在 scheduler() 函数中,这个位置就是进程 p 的 sched() :
1 | // Switch to scheduler. Must hold only p->lock |
总结一下,我们在 sched() 中调用的 swtch() 会返回到 scheduler() 中。相应的,在 scheduler() 中调用 swtch() 会返回到 sched() 中。
这样发生定时器中断后,就会到 scheduler() 中找到可用进程。然后通过 swtch() 把这个可用进程的上下文恢复出来。
这样就可以大致的把进程的切换和调度过程搞清楚了,不过还有一些小细节没有提到。
锁
我们可以注意到, yield() 函数,和 scheduler() 函数,都做了锁相关的操作。那这么做的原因是什么呢?
我们可以先梳理一下 yield() 和 scheduler() 中锁操作的过程。
首先,scheduler() 会给 p->lock() 加锁,然后调用 swtch() 来切换上下文。之后 sched() 会返回到 yield() 函数中,而这个函数会释放 p->lock。
如果发生了定时器中断,那么 yield() 会给进程加锁,随后在 sched() 中调用 swtch() ,返回到 scheduler() 的 swtch() 函数。随后释放进程锁。
和 swtch() 函数相似,进程锁的加锁和释放不在同一个函数中。如果 yield() 给进程加了锁,那一定是 scheduler() 来释放的,反之,如果 scheduler() 加了锁,那一定是 yield() 来释放的。
可以发现进程加锁和解锁的这个区间正是处理器切换上下文的区间。这主要是因为,在进程切换的过程中,线程结构体处于一种不稳定的状态[4]。
比如,我们在 yield() 中把状态标记为了 RUNNABLE,但实际上还没执行 scheduler() 把这个进程切换出去。那如果正好有另一个核心正在执行 scheduler(),寻找 RUNNABLE 的进程,并且发现了当前这个进程,就会有两个处理器同时执行一个进程,这显然是一个严重的错误。
但是加锁后,如果别的核心刚好遇到了这个没切换完的 RUNNABLE 的进程,也不会执行它,因为在 scheduler() 中,我们会试图去得到进程锁,所以在进程真正完成切换前,是会一直阻塞下去的。
同时,加锁和解锁的操作也关闭了中断。这样就避免了我们正在切换进程时,又发生了一个计时器中断(应该不太可能吧)。
第一次调度
通过之前的代码,可以发现,在 scheduler() 中调用 swtch() 会跳转到 sched() 中,是因为这个进程之前因为定时器中断,执行过 sched() 中的 swtch(),而现在这个跳转,实际上是 shced() 中 swtch() 的返回。
但对于第一个进程,或者说刚刚被创建出来的进程来说,以前并没有发生定时器中断。并且我们在 main.c 执行完初始化后就执行了 scheduler(),那么 scheduler() 中的第一次 swtch() 会切换到哪里呢?
这就需要看 allocproc() 函数中的内容了:
1 | // Look in the process table for an UNUSED proc. |
可以看到,进程刚刚被创建的时候,ra 被设成了 forkret。也就是说,第一次被 scheduler() 找到并执行的时候,swtch() 不会跳转到 sched() 中的 swtch() 而是跳转到 forkret() 中。
forkret() 干的事情很简单,其实就是直接返回到用户空间:
1 | // A fork child's very first scheduling by scheduler() |

