upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里:
https://github.com/ttzytt/xv6-riscv
里面不同的分支就是不同的实验。
最后一个 lab 了,终于搞完了!!
Lab11: mmap
描述
实现一个 UNIX 操作系统中常见系统调用 mmap() 和 munmap() 的子集。此系统调用会把文件映射到用户空间的内存,这样用户可以直接通过内存来修改和访问文件,会方便很多。
mmap() 的定义如下:
1 2 void *mmap (void *addr, size_t length, int prot, int flags, int fd, off_t offset) ;
意思是映射描述符为 fd 的文件,的前 length 个字节到 addr 开始的位置。并且加上 offset 的偏移量(即不从文件的开头映射)。
如果 addr 参数为 0,系统会自动分配一个空闲的内存区域来映射,并返回这个地址。
在实验中我们只需要支持 addr 和 offset 都为 0 的情况,也就是完全不用考虑用户指定内存和文件偏移量。
prot 和 flags 都是一些标志位,具体说,prot 有以下的选项:
PROT_NONE
PROT_READ
PROT_WRITE
PROT_EXEC
规定了能对映射后文件做的操作。
flags 则决定,如果在内存映射文件中做了修改,是否要在取消映射时,把这些修改更新到文件中。
有 MAP_SHARED 和 MAP_PRIVATE 两个选项。
unmap() 的定义如下:
1 int munmap (void *addr, size_t length) ;
意思是取消从 addr 开始的,长度为 length 的文件映射。不过需要注意的一点是,这个函数不支持在映射范围的中间“挖洞”,只能从开始或者结尾取消部分(或全部)的映射。
这样说可能有点不清晰,假设我们有一个 [ 1 , 100 ] [1, 100] [ 1 , 100 ] [ l , r ] [l, r] [ l , r ] l = 1 & r ≤ 100 l = 1 \And r \le 100 l = 1 & r ≤ 100 l ≥ 1 & r = 100 l \ge 1 \And r = 100 l ≥ 1 & r = 100
整体思路
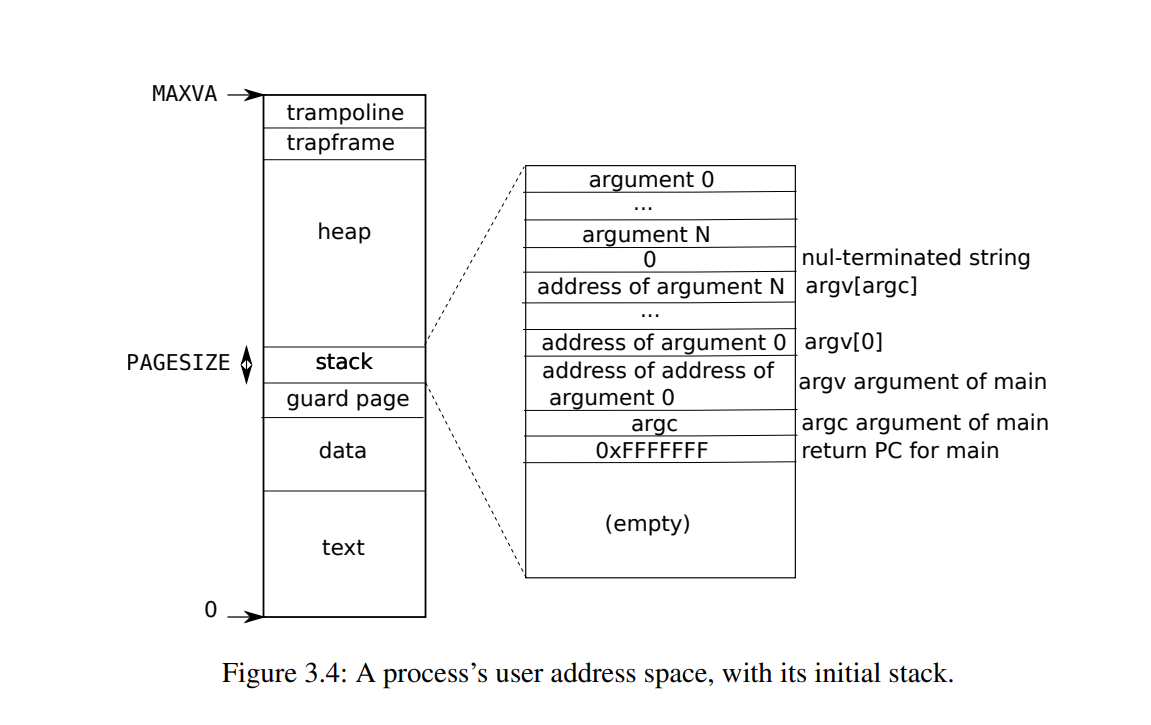
首先我们要考虑把内存映射的文件放在用户进程的哪个地方。用户进程的内存布局如下:
起初我想的是直接参考 sbrk() 的方式来分配映射内存的,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 uint64 sys_sbrk (void ) { int addr; int n; if (argint(0 , &n) < 0 ) return -1 ; addr = myproc()->sz; if (growproc(n) < 0 ) return -1 ; return addr; }
也就是给进程分配更多的堆区,然后把文件放在这里。虽然实现很方便,但是仔细一想会造成很多问题,我们默认 myproc()->sz 以下的内存都是可以给用户自由使用的, malloc() 分配的就是内存。
那么如果我们把映射的文件放在这里,完全可能会被 malloc() 分配出去,再被覆盖掉。
同时,取消文件映射后(这个时候会设置映射位置的 PTE 为 0),如果用户访问了对应位置的内存,还会引发缺页错误,这又需要去处理,显然是比较复杂的。
所以我们完全可以“倒过来”的分配文件映射的内存,来避免和用户进程的堆冲突。也就是说,我们可以从 trapframe 的位置开始,向下分配文件映射的内存。
根据给的提示,可以在内核的进程结构体中加入一个 VMA (virtual memory area, 虚拟内存区域) 结构体,这个结构体储存了文件映射的元数据,比如,映射开始的地址,长度,以及映射的文件等。有了这些元数据才能更方便的管理。
想要同时支持映射多少个文件,就需要在 struct proc 中放多少个 VMA,这里提示给的推荐是 16 个。
文件的映射还必须是懒分配的,要不然一次性拷贝大文件会很耗费时间,只有用户进程触发了缺页错误后,我们才实际的把文件拷贝过去。
最后一点,我们还需要支持在 fork() 的时候也把映射的文件 fork() 过去。当然这点比较简单,只要拷贝 VMA 就行了。因为子进程的页表中没有对应的映射,如果访问 VMA 中记录的地址会引发缺页错误,这个时候只需要把需要的文件拷贝过去就好了。
代码
注意:这个 lab 没有帮我们注册系统调用和 mmaptest,直接按照 Lab2 的方法来就好了,这里不赘述,如果你不会,可以看这篇文章 。
struct mmap_vma:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct mmap_vma { int in_use; uint64 sta_addr; uint64 sz; int prot; struct file * file ; int flags; }; #define VMA_SZ 16 struct proc { …… struct mmap_vma mmap_vams [VMA_SZ ]; }
sys_mmap():
这个调用不实际的分配内存。其调用 get_mmap_space() 找到一个没被使用的 mmap_vams,以及用于映射文件的空间,再给 vma 结构体初始化。
还需要增加被映射文件的引用计数(如果不增加,引用计数为 0 后,文件会被关闭,然后我们在懒分配的时候就无法拷贝对应文件内容到内存了)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 uint64 sys_mmap () { uint64 addr, length, offset; int prot, flags, fd; struct file * file ; try(argaddr(0 , &addr), return -1 ) try(argaddr(1 , &length), return -1 ) try(argint(2 , &prot), return -1 ) try(argint(3 , &flags), return -1 ) try(argfd(4 , &fd, &file), return -1 ) try(argaddr(5 , &offset), return -1 ) struct proc * p = if (addr || offset) return -1 ; if (!file->writable && (prot & PROT_WRITE) && (flags & MAP_SHARED)) return -1 ; int unuse_idx = -1 ; uint64 sta_addr = get_mmap_space(length, p->mmap_vams, &unuse_idx); if (unuse_idx == -1 ) return -1 ; if (sta_addr <= p->sz) return -1 ; struct mmap_vma * cur_vma = cur_vma->file = file; cur_vma->in_use = 1 ; cur_vma->prot = prot; cur_vma->flags = flags; cur_vma->sta_addr = sta_addr; cur_vma->sz = length; filedup(file); return cur_vma->sta_addr; }
get_mmap_space():
此函数需要给新的文件映射找到一个可用的内存区域,那么我们需要思考一下这个策略。最稳的方法肯定是找到所有 vma 中使用到的最低虚拟地址。然后把这个位置作为新映射区域的结尾。这样永远不会造成冲突,不过也有一定问题,如下:
首先可以看到,为了方便取消映射,我们不允许同一个页帧上有两个文件的映射(要不然 kfree() 就一起释放了)。
其次,如果我们使用了找最低虚拟地址的方法来分配,就会造成实际内存够用,却还要向下增长文件映射空间的情况。这样的策略可能在某些情况下(较少)会造成用户堆内存的缩减,在极端情况下(非常极端,因为大部分时候 MAXVA 都是很大的,至少比物理内存大),是会出问题的。
但不管怎么样,我闲的没事干还是写了一个应对这种情况的代码。大概就是搞个双层循环,每层都遍历所有的 vma,具体的可以见注释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 uint64 get_mmap_space (uint64 sz, struct mmap_vma* vmas, int * free_idx) { *free_idx = -1 ; uint64 lowest_addr = TRAPFRAME; struct mmap_vma tmp ; tmp.sta_addr = TRAPFRAME, tmp.sz = 0 ; for (int i = 0 ; i <= VMA_SZ; i++){ if (vmas[i].in_use == 0 && i != VMA_SZ){ *free_idx = i; continue ; } uint64 ed_pos = i != VMA_SZ ? PGROUNDDOWN(vmas[i].sta_addr) : tmp.sta_addr; lowest_addr = ed_pos < lowest_addr ? ed_pos : lowest_addr; for (int j = 0 ; j < VMA_SZ; j++){ if (vmas[j].in_use == 0 && i != VMA_SZ) continue ; uint64 st_pos = i != VMA_SZ ? vmas[j].sta_addr + vmas[j].sz : tmp.sta_addr + tmp.sz; if (ed_pos <= st_pos) continue ; if (ed_pos - st_pos >= sz){ return st_pos; } } } return lowest_addr - sz; }
到此为止我们所有的映射都是懒分配的,所以需要一个处理缺页错误的函数:
mmap_fault_handler():
注意这里有个比较坑的地方。就是用户要求映射的大小超过了文件本身的大小,这个时候我们需要把剩下的映射区域设成 0,要不然 mmaptest() 就通不过了。
还有一点就是,触发缺页错误后我们只分配和映射一页内存,而不是把整个文件都映射过去。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 int mmap_fault_handler (uint64 addr) { struct proc * p = struct mmap_vma * cur_vma ; if ((cur_vma = get_vma_by_addr(addr)) == 0 ){ return -1 ; } if (!cur_vma->file->readable && r_scause() == 13 && cur_vma->flags & MAP_SHARED){ DEBUG("mmap_fault_handler: not readable\n" ); return -1 ; } if (!cur_vma->file->writable && r_scause() == 15 && cur_vma->flags & MAP_SHARED){ DEBUG("mmap_fault_handler: not writable\n" ); return -1 ; } uint64 pg_sta = PGROUNDDOWN(addr); uint64 pa = kalloc(); if (!pa){ DEBUG("mmap_fault_handler: kalloc failed\n" ); return -1 ; } memset (pa, 0 , PGSIZE); int perm = PTE_U | PTE_V; if (cur_vma->prot & PROT_READ) perm |= PTE_R; if (cur_vma->prot & PROT_WRITE) perm |= PTE_W; if (cur_vma->prot& PROT_EXEC) perm |= PTE_X; uint64 off = PGROUNDDOWN(addr - cur_vma->sta_addr); ilock(cur_vma->file->ip); int rdret; if ((rdret = readi(cur_vma->file->ip, 0 , pa, off, PGSIZE)) == 0 ){ iunlock(cur_vma->file->ip); return -1 ; } iunlock(cur_vma->file->ip); mappages(p->pagetable, pg_sta, PGSIZE, pa, perm); return 0 ; }
get_vma_by_addr():
此函数是前面的处理函数用到的,返回对应地址所在的 vma:
1 2 3 4 5 6 7 8 9 10 11 struct mmap_vam* get_vma_by_addr (uint64 addr) { struct proc * p = for (int i = 0 ; i < VMA_SZ; i++){ if (p->mmap_vams[i].in_use && addr >= p->mmap_vams[i].sta_addr && addr < p->mmap_vams[i].sta_addr + p->mmap_vams[i].sz){ return p->mmap_vams + i; } } return 0 ; }
usertrap():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 …… if (r_scause() == 8 ){ if (p->killed) exit (-1 ); p->trapframe->epc += 4 ; intr_on(); syscall(); } else if ((which_dev = devintr()) != 0 ){ } else if ((r_scause() == 13 || r_scause() == 15 )){ try(mmap_fault_handler(r_stval()), bad = 1 ) } else { bad = 1 ; } if (bad){ printf ("usertrap(): unexpected scause %p pid=%d\n" , r_scause(), p->pid); printf (" sepc=%p stval=%p\n" , r_sepc(), r_stval()); p->killed = 1 ; } ……
接下来我们就可以来尝试实现 munmap() 了,如果 vma 的 flag 设置为了 MAP_SHARED,就需要在取消映射的时候拷贝内存中修改过的内容到文件。
因为这个过程相对复杂,所以专门写了一个 mmap_writeback() 函数来处理这个。其中,我们利用了 PTE 的标志位 PTE_D 来判断文件映射的某个页帧是否被修改过,如果修改过,就需要拷贝回去。
这个标志位没被定义,需要参考 risc-v 手册在 riscv.h 中定义:
如果说 unmap 的 addr 和长度不是 PGSIZE 的倍数,那么这个函数会变得特别复杂,如下:
unmap 的部分可能没有跨过一个页帧,也就是说 unmap 的所有内存都在一个页帧之内,那么这个页帧不能释放,但是需要把内存中的数据复制回文件。
对于 unmap 结尾地址在某个页帧中间的情况,需要分类讨论。如果结尾是中间,但这个页帧是映射区的最后一个页帧,那既需要释放页帧,也许要写回文件。如果是中间,但不是最后一个页帧,那就不能释放。
可能也是考虑到了这个复杂度,mmaptest.c 中所有 munmap() 和 mmap() 调用的 addr 和 len 都是 PGSIZE 的倍数。实验提示中也说只要支持 mmaptest.c 使用到的特性就行了。所以下面的版本是不支持非 PGSIZE 倍数的。当然我也写了一个支持的版本,只是没有经过任何测试(我懒的再写一个加强版的 mmaptest.c,当然以后有时间,可能会)。
正常版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int mmap_writeback (pagetable_t pt, uint64 src_va, uint64 len, struct mmap_vma* vma) { uint64 a; pte_t *pte; for (a = PGROUNDDOWN(src_va); a < PGROUNDDOWN(src_va + len); a += PGSIZE){ if ((pte = walk(pt, a, 0 )) == 0 ){ panic("mmap_writeback: walk" ); } if (PTE_FLAGS(*pte) == PTE_V) panic("mmap_writeback: not leaf" ); if (!(*pte & PTE_V)) continue ; if ((*pte & PTE_D) && (vma->flags & MAP_SHARED)){ begin_op(); ilock(vma->file->ip); uint64 copied_len = a - src_va; writei(vma->file->ip, 1 , a, copied_len, PGSIZE); iunlock(vma->file->ip); end_op(); } kfree(PTE2PA(*pte)); *pte = 0 ; } return 0 ; }
支持非 PGSIZE 倍数版本(未经测试):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 int mmap_writeback_na (pagetable_t pt, uint64 src_va, uint64 len, struct mmap_vma* vma) { uint64 a; pte_t *pte; a = PGROUNDDOWN(src_va); if (a == PGROUNDDOWN(src_va + len)){ begin_op(); ilock(vma->file->ip); writei(vma->file->ip, 1 , src_va, 0 , src_va - a); iunlock(vma->file->ip); end_op(); } for (; a < PGROUNDDOWN(src_va + len); a += PGSIZE){ if ((pte = walk(pt, a, 0 )) == 0 ){ panic("mmap_writeback: walk" ); } if (PTE_FLAGS(*pte) == PTE_V) panic("mmap_writeback: not leaf" ); if (!(*pte & PTE_V)) continue ; if ((*pte & PTE_D) && (vma->flags & MAP_SHARED)){ begin_op(); ilock(vma->file->ip); uint64 copied_len = a - src_va; if (a < src_va){ writei(vma->file->ip, 1 , src_va, 0 , src_va - a); } else { writei(vma->file->ip, 1 , a, copied_len, PGSIZE); } iunlock(vma->file->ip); end_op(); } kfree(PTE2PA(*pte)); *pte = 0 ; } uint64 copied_len = a - src_va; uint64 len_left = vma->sz - copied_len; if (len_left){ begin_op(); ilock(vma->file->ip); writei(vma->file, 1 , a, copied_len, len_left); if (len_left + a == vma->sz + src_va){ pte_t *pte; if ((pte = walk(pt, a, 0 )) == 0 ){ panic("mmap_writeback: walk" ); } kfree(PTE2PA(*pte)); } iunlock(vma->file->ip); end_op(); } return 0 ; }
相比之下,munmap() 就比较简单了,但需要注意,如果 unmap 好了之后整个映射区都没了,就代表我们不需要再用到对应的文件了,所以调用 fileclose() 来减少引用计数和关闭文件。
同时,还不能忘记 munmap() 取消映射区时的限制,只能从头取消或者是结尾,不能中间挖洞(见本文开头)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 uint64 munmap (uint64 addr, uint64 len) { struct proc * p = struct mmap_vma * cur_vma = if (!cur_vma) return -1 ; if (addr > cur_vma->sta_addr && addr + len < cur_vma->sta_addr + cur_vma->sz){ return -1 ; } mmap_writeback(p->pagetable, addr, len, cur_vma); if (addr == cur_vma->sta_addr){ cur_vma->sta_addr += len; } cur_vma->sz -= len; if (cur_vma->sz <= 0 ){ fileclose(cur_vma->file); cur_vma->in_use = 0 ; } return 0 ; }
可能你会发现这个函数不是系统调用的形式,这是因为我们之后还需要在内核中调用。系统调用的形式如下:
1 2 3 4 5 6 7 8 9 uint64 sys_munmap () { uint64 addr; uint64 len; try(argaddr(0 , &addr), return -1 ) try(argaddr(1 , &len), return -1 ) return munmap(addr, len); }
内核需要调用 munmap() 是因为有些进程在退出后还没有取消它的文件映射,那我们就需要帮它强制清理掉这些映射,要不然会造成内存泄露,这个清理可以放在 exit() 中。
这里讲一下为为什么放在 exit() 中而不是真正释放进程号的 freeproc()。我们可以观察一下,一个进程被 freeproc() 是在 wait() 函数中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 …… for (;;){ havekids = 0 ; for (np = proc; np < &proc[NPROC]; np++){ if (np->parent == p){ acquire(&np->lock); havekids = 1 ; if (np->state == ZOMBIE){ pid = np->pid; if (addr != 0 && copyout(p->pagetable, addr, (char *)&np->xstate, sizeof (np->xstate)) < 0 ) { release(&np->lock); release(&wait_lock); return -1 ; } freeproc(np); release(&np->lock); release(&wait_lock); return pid; } release(&np->lock); } } …… } ……
那么如果父进程不调用 wait() 这些映射的文件就一直放着不会被写会文件中。当然,父进程是应该调用 wait() 的,这里放在 exit() 中主要还是实验的提示,但实验提示这么写可能是这个原因。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void exit (int status) { struct proc *p = if (p == initproc) panic("init exiting" ); for (int i = 0 ; i < VMA_SZ; i++){ if (p->mmap_vams[i].in_use){ try(munmap(p->mmap_vams[i].sta_addr, p->mmap_vams[i].sz), panic("exit: munmap" )); } } for (int fd = 0 ; fd < NOFILE; fd++){ if (p->ofile[fd]){ struct file *f = fileclose(f); p->ofile[fd] = 0 ; } } …… }
实验的最后一步就是在 fork() 之后也能让子进程访问到映射的文件。前面提到过我们只需要拷贝 vma 就行了。vma 中的 sta_addr 是一个虚拟地址,那么子进程尝试访问的时候会造成缺页错误,因为这个虚拟地址没有映射到物理地址上。
因此在 mmap_fault_handler() 中,我们会发现触发缺页错误的这个地址属于一个文件映射区。因此会给这个虚拟页帧分配一个物理页,然后把对应文件拷贝过去。
当然 fork() 之后意味着有另外一个进程也在使用被映射的文件,所以需要调用 filedup() 来增加引用计数。
fork():
1 2 3 4 5 6 7 8 9 10 …… for (int i = 0 ; i < VMA_SZ; i++){ if (p->mmap_vams[i].in_use){ np->mmap_vams[i] = p->mmap_vams[i]; filedup(p->mmap_vams[i].file); } } ……
我最初在这里有个小问题,就是前面的 uvmcopy() 已经复制过内存了,那难道不会把 vma 也复制了吗,我们后面再复制是否会造成重复复制。
看了代码之后就解决了,uvmcopy() 只会复制 myproc()->sz 以下的内存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 for (i = 0 ; i < sz; i += PGSIZE){ if ((pte = walk(old, i, 0 )) == 0 ) panic("uvmcopy: pte should exist" ); if ((*pte & PTE_V) == 0 ) panic("uvmcopy: page not present" ); pa = PTE2PA(*pte); flags = PTE_FLAGS(*pte); if ((mem = kalloc()) == 0 ) goto err; memmove(mem, (char *)pa, PGSIZE); if (mappages(new, i, PGSIZE, (uint64)mem, flags) != 0 ){ kfree(mem); goto err; } }
做好之后就可以 AC 了,也祝正在做这个 lab 的人尽快 AC:
吐槽
这里我一定要吐槽一下 (我都不知道是哪的 bug,xv6?qemu?还是 Makefile?)的一个 bug。
大概就是我在用 gdb 调试的时候希望能使用宏(主要是 PGROUNDDOWN() 和 PGROUNDUP()),所以在 Makefile 文件中加入了 -g3 编译选项,像下面这样:
1 CFLAGS = -Wall -O -g3 -fno-omit-frame-pointer -ggdb -UFDEBUG
而这就会导致 usertest.c 中的一个测试通不过,直接 panic 了,如下:
1 2 3 $ usertests writebig usertests starting test writebig: panic: balloc: out of blocks
去掉这个 -g3 居然就正常了???我是怎么也想不到一个编译选项居然可以影响虚拟磁盘的块数。然后就因为这个东西调了一天没调出来,毕竟谁会想到一个编译选项有这种效果,后来我是直接用 git 看这个分支和别的分支文件的区别,然后一个一个试才试出来的。
这个问题我已经发在 xv6-riscv 的 github 上了,然后在 issue 区逛了一圈后还发现了更离谱的:
https://github.com/mit-pdos/xv6-riscv/issues/59
就是在编译选项里加一个 -O3 也会造成这个问题。。。我不李姐。。。





![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)