C. Mark and His Unfinished Essay
思路
这个数据范围显然不能真的去复制字符串,所以要找到一些别的方法。
可以发现,每次在字符串末尾新加上的那一段,都可以通过一个偏移量在前面找到一模一样的。
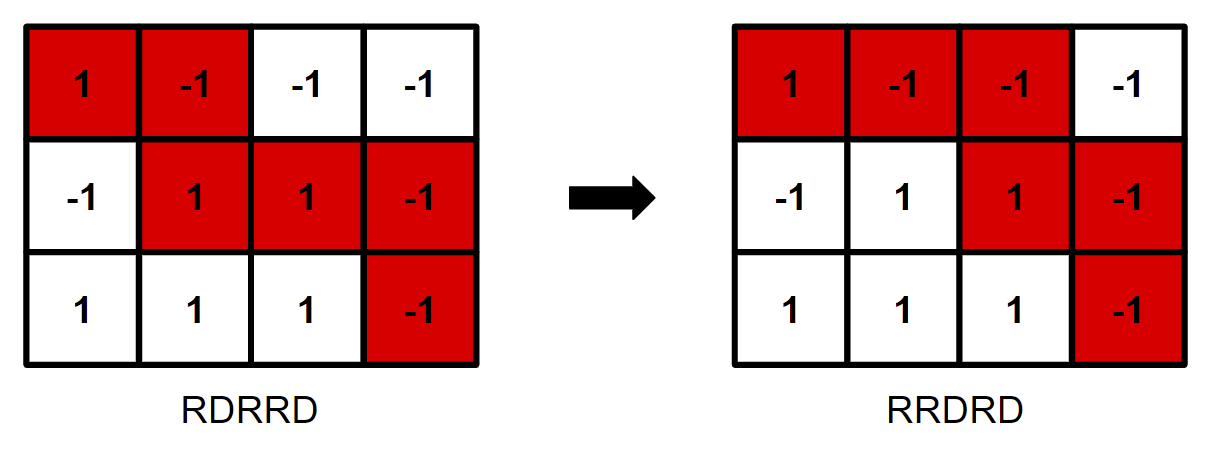
比如我们可以观察样例中第一个数据的最后一次插入:
mark mark mar rkmark \texttt{mark\ mark\ mar\ } \color{red}{\texttt{rkmark}}
mark mark mar rkmark
把这个 rkmark \texttt{rkmark} rkmark 9 9 9 rkmark \texttt{rkmark} rkmark
ma rkmark mar rkmark \texttt{ma\ } \textcolor{red}{\texttt{rkmark\ }}\texttt{mar\ } \textcolor{red}{\texttt{rkmark}}
ma rkmark mar rkmark
所以我们可以维护一个三元组 ( l , r , d ) (l, r, d) ( l , r , d ) [ l , r ] [l, r] [ l , r ] [ l − d , r − d ] [l - d, r - d] [ l − d , r − d ]
这样每次在查询位置 x x x d d d x x x
这里再说明一下
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <bits/stdc++.h> using namespace std;#define ll long long struct Seg { ll l, r, diff; }; int main () int t; cin >> t; while (t--) { int n, c, q; cin >> n >> c >> q; string str; cin >> str; vector<Seg> a (c + 1 ) ; a[0 ].l = 0 , a[0 ].r = n - 1 ; for (int i = 1 ; i <= c; i++) { ll l, r; cin >> l >> r; l--, r--; a[i].l = a[i - 1 ].r + 1 ; a[i].r = a[i].l + (r - l); a[i].diff = a[i - 1 ].r - l + 1 ; } while (q--) { ll x; cin >> x; x--; for (int i = c; i >= 1 ; i--) { if (x < a[i].l) continue ; else x -= a[i].diff; } cout << str[x] << '\n' ; } } }
D. Mark and Lightbulbs
思路
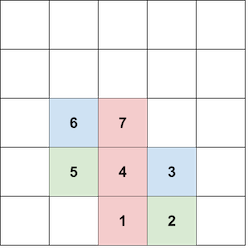
先来模拟一下第四个样例:
000101 ↓ 00 1 101 ↓ 0 1 1101 ↓ 011 0 01 ↓ 01 0 001 ↓ 0100 1 1 \texttt{000101} \\
\downarrow\\
\texttt{00}\textcolor{red}{\texttt{1}}\texttt{101}\\
\downarrow\\
\texttt{0}\textcolor{red}{\texttt{1}}\texttt{1101}\\
\downarrow\\
\texttt{011}\textcolor{red}{\texttt{0}}\texttt{01}\\
\downarrow\\
\texttt{01}\textcolor{red}{\texttt{0}}\texttt{001}\\
\downarrow\\
\texttt{0100}\textcolor{red}{\texttt{1}}\texttt{1}\\
000101 ↓ 00 1 101 ↓ 0 1 1101 ↓ 011 0 01 ↓ 01 0 001 ↓ 0100 1 1
注:标红的位置表示发生了变化。
可以发现,这个过程中我们只能将一个由 1 1 1 1 \texttt{1} 1 111 \texttt{111} 111 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 s i − 1 s_{i - 1} s i − 1 s i + 1 s_{i + 1} s i + 1 s i s_i s i
所以我们可以知道,如果 s s s t t t s s s t t t
可以发现,每一次操作中,我们能将一个 “ 1 1 1 s s s t t t
也就是,对于 s s s t t t s s s t t t
那如何判断段的开始和结尾呢?无非就是 0 0 0 1 1 1 1 1 1 0 0 0 a a a b b b s s s t t t s i ≠ s i + 1 s_i \ne s_{i + 1} s i = s i + 1 i i i a a a t t t b b b a a a b b b
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <bits/stdc++.h> using namespace std;#define ll long long int main () int t; cin >> t; while (t--) { string s, t; int n; cin >> n >> s >> t; vector<int > sdiff, tdiff; ll ans = 0 ; if (s.front () != t.front () || s.back () != t.back ()) { goto FAIL; } for (int i = 0 ; i < s.size () - 1 ; i++) { if (s[i] != s[i + 1 ]) sdiff.push_back (i); if (t[i] != t[i + 1 ]) tdiff.push_back (i); } if (sdiff.size () != tdiff.size ()) { goto FAIL; } else { for (int i = 0 ; i < sdiff.size (); i++) { ans += abs (sdiff[i] - tdiff[i]); } } SUCC: cout << ans << '\n' ; continue ; FAIL: cout << "-1\n" ; } }


![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)