CF1705 C, D 题解
C. Mark and His Unfinished Essay
思路
这个数据范围显然不能真的去复制字符串,所以要找到一些别的方法。
可以发现,每次在字符串末尾新加上的那一段,都可以通过一个偏移量在前面找到一模一样的。
比如我们可以观察样例中第一个数据的最后一次插入:
把这个 中的每个字母都向前移动 个位置,就是另一个 ,如下:
所以我们可以维护一个三元组 ,表示 这段区间内的字符,和 这段区间内的字符完全一样。
这样每次在查询位置 的时候,我们就可以一直减去相应的 ,直到 被包含在初始字符串的范围内。
这里再说明一下
代码
1 | // ttzytt |
D. Mark and Lightbulbs
思路
先来模拟一下第四个样例:
1 | 000101 |
注:标红的位置表示发生了变化。
可以发现,这个过程中我们只能将一个由 组成的段,比如 ,或者 (当然反过来看的话可以说是 组成的段)延长或者是缩短一点,而不能凭空创造出一个新的“ 段”。这是因为,只有从 变成了 或者从 变成了 , 和 才会是不一样的,我们才能改变 。
所以我们可以知道,如果 串和 串的段数量不一样,那么一定是不可能从 转换成 的。
可以发现,每一次操作中,我们能将一个 “ 段” 的开头或者结尾移动一个位置,那么用这个方式就可以计算出从 到 的变换需要多少步了。
也就是,对于 和 中的每一个段,我们计算出段开始和结尾的位置,然后再算出 中和 中的段端点的差,把这些差累加起来就是答案了。
那如何判断段的开始和结尾呢?无非就是 变成 和 变成 。所以我们开两个数组 和 ,输入 和 之后遍历一遍这两个字符串。只要 ,就把 放入 中(对于 和 相同)。这样 和 中就存了两个串的所有段端点。
代码:
1 |
|
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 tzyt的博客!
相关推荐
2022-06-16
CF1692G题解
题目链接(CF,洛谷) | 强烈推荐博客中观看。 打的第一场 CF div.4 这个题就是那种想到点了就很很简单,没想到的话就……寄了的题(我就属于是寄了)。 1. 题意: 给你一个长度为 n (∑n<2⋅105)n \ (\sum n < 2\cdot 10^5)n (∑n<2⋅105) 的数组 aaa,问你在这个数组中,有多少个长度为 k+1 (1≤k<n)k + 1 \ (1\le k < n)k+1 (1≤k<n) 的区间,符合以下的条件: 20⋅ai<21⋅ai+1<22⋅ai+2< ⋯<2k⋅ai+k注:i为这个区间开始的位置2^0 \cdot a_i < 2^1 \cdot a_{i + 1} < 2^2 \cdot a_{i + 2} < \dotsi < 2^k \cdot a_{i + k}\\ \footnotesize{注:i 为这个区间开始的位置} 20⋅ai<21⋅ai+1<22⋅ai+2<⋯<2k⋅ai+k注:i为这个区间开始的位置...
2022-12-17
CF1774C 题解
吐槽一下,官方题解写的挺难看懂的,看了好久还是挺迷糊的(其实也是我太菜了)。搞懂之后感觉这题挺妙的,来写下题解。 思路 我们首先需要有一个观察,就是对于 sss 串,最后一个连续字串不会增加可能的获胜人数。比如 s=0011s = \texttt{0011}s=0011 时,后面结尾的 11\texttt{11}11 就不会增加可能的获胜人数。 为啥呢,设我们设经过任意次数对战后,玩家可能组合的集合为 ttt 那么对于任意的 x∈tx \in tx∈t,连续在环境 111 中对战任意次数后,最终的赢家一定是 xxx 中温度最高的(因为每个剩下的玩家都会需要连续在环境 111 中对战,唯一能胜出所有对战的玩家一定是最大的)。同理,ttt 中的玩家连续在环境 000 中对战任意次数后,最终的赢家一定是 xxx 中温度最低的。 例如,s=111s = \texttt{111}s=111 时,最后胜出的一定是 444 号玩家。 这样一来,如果结尾段是 111(000 结尾同理,后面为了方便先用 111 的例子了),我们只需要算出前面的部分最多能构造出多少种最大值(玩家温度)不同的玩家组合...
2022-06-13
CF1665C题解
题目链接 博客中观看体验更佳 1.题意: 给你一个有 nnn 个节点的树,一开始,每个节点都是健康的。每秒钟你可以进行下面两种操作: 传播:对于一个节点,如果它的至少一个子节点被感染了,那么可以感染它的另一个子节点。(如果有多个节点符合条件,那一秒钟就可以传播多个节点) 注射:你可以任选树中的一个节点进行感染。(一秒钟只能多感染一个节点) 现在问你最少需要多少秒才能感染整个树。 2.思路: 看完题我们要注意到,这个题说的是节点可以把病毒传播给他们的兄弟节点,而不是传播给他们的子节点,所以这个树的每一层之间是完全独立的,不可能把病毒从一层传播给另一层。 所以我们肯定需要在一开始的时候就给每个节点的至少一个子节点注射病毒(具体哪个不重要),这样每秒钟能感染的节点更多(根据操作 1)。 那先给谁的子节点注射呢?考虑先被注射的子节点会有更多的时间把病毒传播给更多的子节点。所以我们应该先给子节点更多的节点注射病毒。 (如果先给子节点少的节点注射,那在给所有节点注射完之前,这个节点的所有子节点可能都被感染了,也就是有很多时间被浪费了)。 在确保每个节点都有至少一个子节点被注射后,我们还可...
2022-07-18
CF1705 B, C, D1 题解
B. Making Towers 思路 观察题面上给第一个样例提供的图: 可以发现,如果我们要让某种颜色形成一个塔,除非多个相同颜色在 ccc 数组中挨在一起,可以直接向上排布。就一定需要在排布该颜色后,向两侧放一些其他颜色,然后又往相反方向放置,最后使得两个颜色相同的块在一条直线上,大概是下面这样: 1234⬆->->->A⬆<-<-<-A<-<-<-⬆ A->->->⬆ 1 2 ... z 其中, AAA 表示一个颜色的塔,而箭头表示放置颜色块的路径。 观察发现,在放置两个 AAA 之间,需要放置偶数个其他颜色块,下面是解释: 假设第一个 AAA 的位置是 (x,y)(x, y)(x,y),并且我们往右侧放置的其他颜色块的数量是(也可以是左侧) zzz。 那么为了把第二个 AAA 搞到 (x,y+1)(x, y + 1)(x,y+1) 上,就需要在 (x+1,y)∼(x+z,y)(x + 1, y) \sim (x + z, y)(x+1,y)∼(x+z,y) 和 (x+1,...
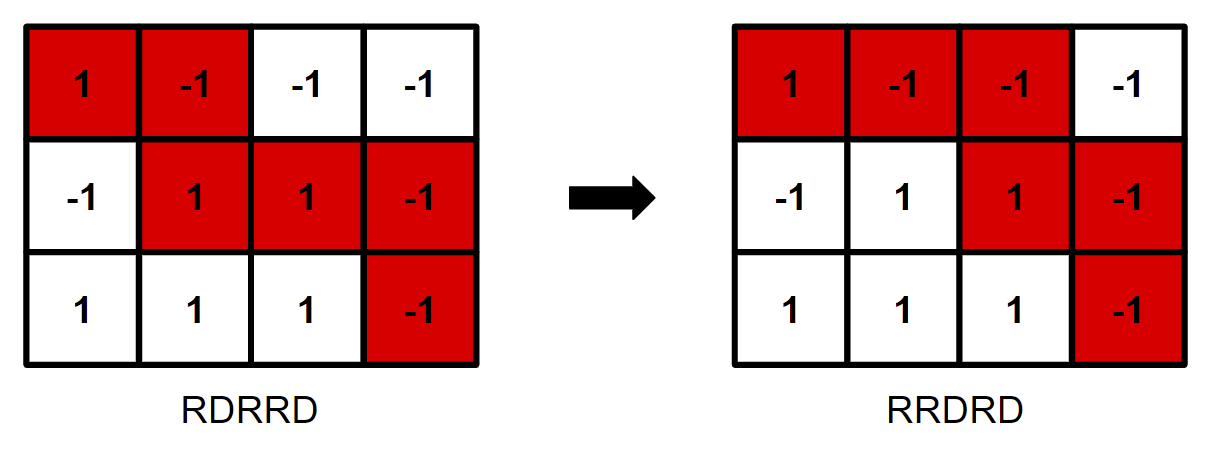
2022-06-22
CF1695C题解
题目链接(CF,洛谷) | 强烈推荐博客中观看。 题意 给你一个 n×mn \times mn×m (1≤n,m≤10001 \le n, m \le 10001≤n,m≤1000) 的格点图,每个格子的值要么是 −1-1−1,要么是 111,现在问你,是否有一条从 (1,1)(1, 1)(1,1) 到 (n,m)(n, m)(n,m) 的路径,使得路径上经过的格点的值的和为 000。在路径中,只能从 ai,ja_{i, j}ai,j 移动到 ai+1,ja_{i + 1, j}ai+1,j 或是 ai,j+1a_{i, j + 1}ai,j+1(向右或是向下走)。 思路 看到这个 (1≤n,m≤10001 \le n, m \le 10001≤n,m≤1000) 的数据范围就知道暴搜肯定要寄了(别学我),所以得想一些别的办法。 首先,如果经过奇数个格子,或者说 n+m−1n + m - 1n+m−1 为奇数,那么肯定没有这样的一条路径(经过的 −1-1−1 和 111 点没有办法相等)。 直接判断某个格子图是否符合要求太麻烦,我们可以思考,如果有任意一条路径,我们是否能根...
2022-07-04
CF1699C题解
题目链接(CF,洛谷) | 强烈推荐博客中观看。 这题是真的难想,我 cf 的题解看了好久才搞明白(我太菜了)。 题意 给你一个长度为 nnn 的排列 aaa,请你找出有多少个相同长度的排列 bbb 和 aaa 相似。 如果对于所有区间 [l,r](1≤l≤r≤n)[l, r] (1 \le l \le r \le n)[l,r](1≤l≤r≤n),下面的条件满足: MEX(al,al+1,…,ar)=MEX(bl,bl+1,…,br)\operatorname{MEX}(a_l, a_{l + 1}, \ldots , a_r) = \operatorname{MEX}(b_l, b_{l + 1}, \ldots , b_r) MEX(al,al+1,…,ar)=MEX(bl,bl+1,…,br) 我们就称排列 aaa 和 bbb 是相似的。 其中 MEX\operatorname{MEX}MEX 对于数组 ccc 的定义是:最小的,没有出现在 ccc 中的非负整数 xxx。 例如 MEX([1,2,3,4,5])=0 MEX([0,1,2,4,5])=...
评论

