[MIT 6.s081] Xv6 Lab4 Traps 实验记录
前言:今天是 2022/7/25 先庆祝一下博客运行 100 天了。
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里:
https://github.com/ttzytt/xv6-riscv
里面不同的分支就是不同的实验。
Lab4: traps
RISC-V assembly
先鸽了
Backtrace
实现一个backtrace()的函数,如果某个程序调用了这个函数,该函数应该输出这个程序的 “函数调用顺序”,也就是把当前栈中的函数地址按照先后顺序全部打印出来。
做这个实验最主要的还是需要了解函数调用的过程,具体可以参考我之前写的这篇文章。
这里我把那篇文章中最重要的图和视频放在下面(绝对不是水字数),如果你之前比较熟悉函数调用的过程,但是现在忘了,看了之后应该比较容易回忆起来。
实验中,我们需要把函数调用的一个 “链条” 打印出来。
比如有下面这个程序:
1 | int third(int x){ |
那么调用 backtrace() 后的正确输出应该是
1 | 114 |
其实就是让我们把函数调用者的地址递归的打印下去。
那我们知道,每个栈帧中都储存了当前函数的返回地址。(也就是,这个函数执行好了,应该返回到哪里)。
所以可以直接把每个栈帧中的返回地址打印出来。还应该开一个变量储存当前帧指针的位置,通过这个帧指针加上一些偏移量,获取上一个函数的帧指针,就可以打印上一个函数的返回地址了。
不过要注意的是,在我原来那篇文章中,使用的是 x86 (x64) 架构的处理器,其帧指针的名称为 bp (base pointer) 寄存器,在 riscv 中,fp (frame pointer) 寄存器做了相同的工作。
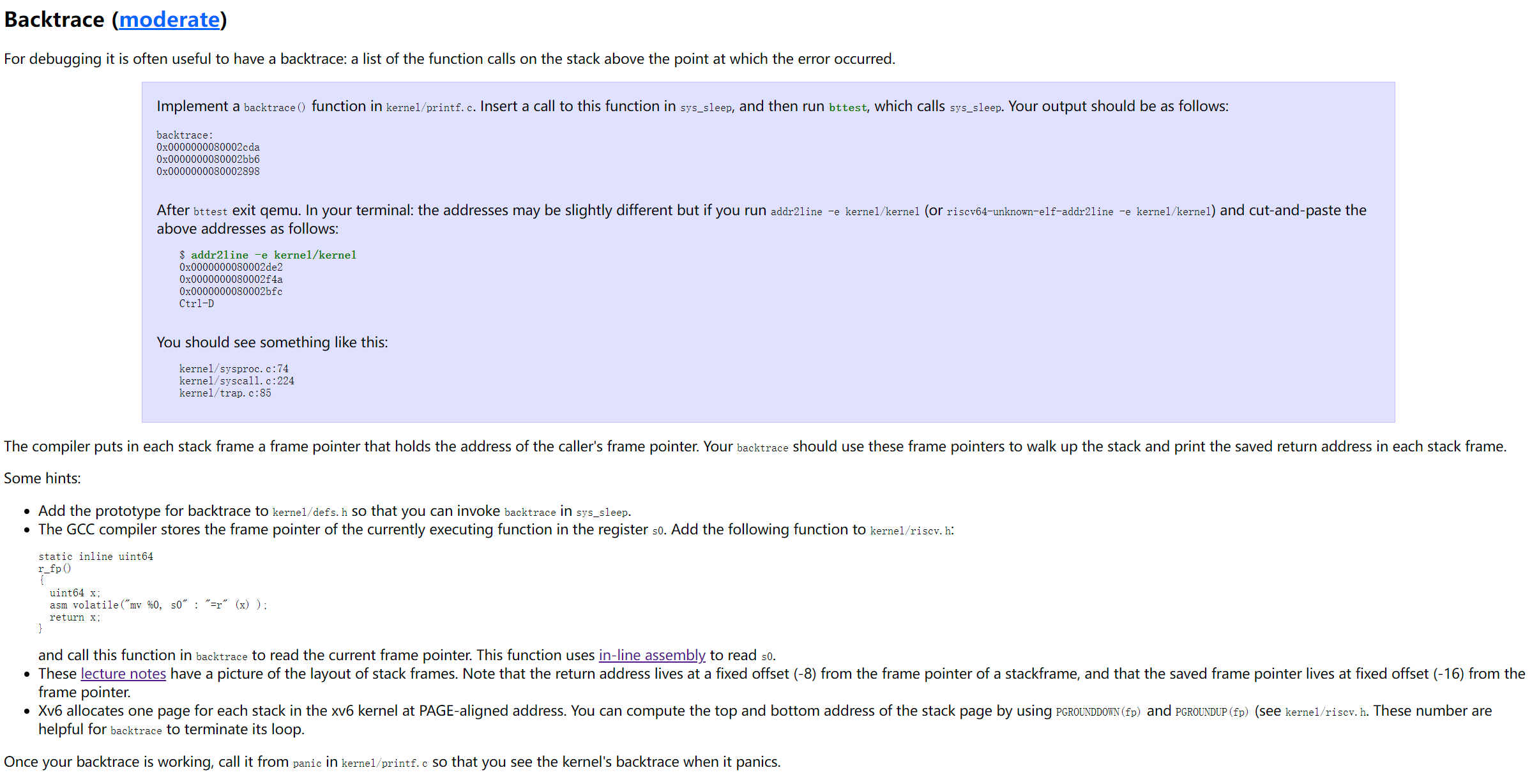
并且 riscv 中的 fp 指向的位置也和 x86 中的略有不同,具体可以看下面这张图[1]:
1 | 高地址 |
可以发现,在 riscv 中,fp 指向的是当前栈帧返回地址前面的一个位置(地址更高)。但是在 x86 中,bp 指向的是前一个栈帧的 bp 寄存器。
这个大概是因为 x86 和 riscv 对于一个栈帧定义的不同。在 riscv 的定义中,返回地址也是属于当前栈帧的的一部分(说实话我觉得这个设计更合理)。
虽然我们总是可以通过 fp 获得函数的返回地址,但是还需要获得到当前的 fp,这就需要用到 c 语言的内嵌汇编了,我们可以把这个函数放到 kernel/riscv.h 里:
1 | static inline uint64 |
GCC 拓展内联汇编的基本格式是:
1 | asm asm-qualifiers ( AssemblerTemplate |
其中,asm 代表着内联汇编的开始,asm-qualifiers 表示这个内联汇编的一些性质,比如我们这里加了 volatile 就表示不希望 GCC 把这个汇编优化掉。
在上面的 ("mv %0, s0" : "=r" (x) ) 中,mv %0, s0 是一个汇编的模板,并不是真正的汇编,有点类似于 C++ 中的模板,在编译的时候会把类型替换掉。GCC 编译的时候也会把 %0 这个东西替换成后面 : "=r" (x) 规定的变量(这里是 x)所在的寄存器。
而这个 "=r" 代表了一种限制条件,里面的 r 表示这个 x 变量可以在任何的通用寄存器中,而等于号表明该变量是被写入的。
除了 r,还有很多种限制条件[2],比如 m 代表了该变量可以储存在内存中。如果你还想了解更多的限制条件,可以参考 GCC 的文档。
GCC 的文档中对拓展内联汇编也有非常详细的解释。
所以,总的来说,r_fp() 这个函数读出了 s0 这个寄存器的值,然后储存在 x 中,最后又把 x 返回了。
但是我们要读取的明明是 fp 这个寄存器,为什么这个函数里写的是 s0 呢,具体可以看看下面这个表[3]:
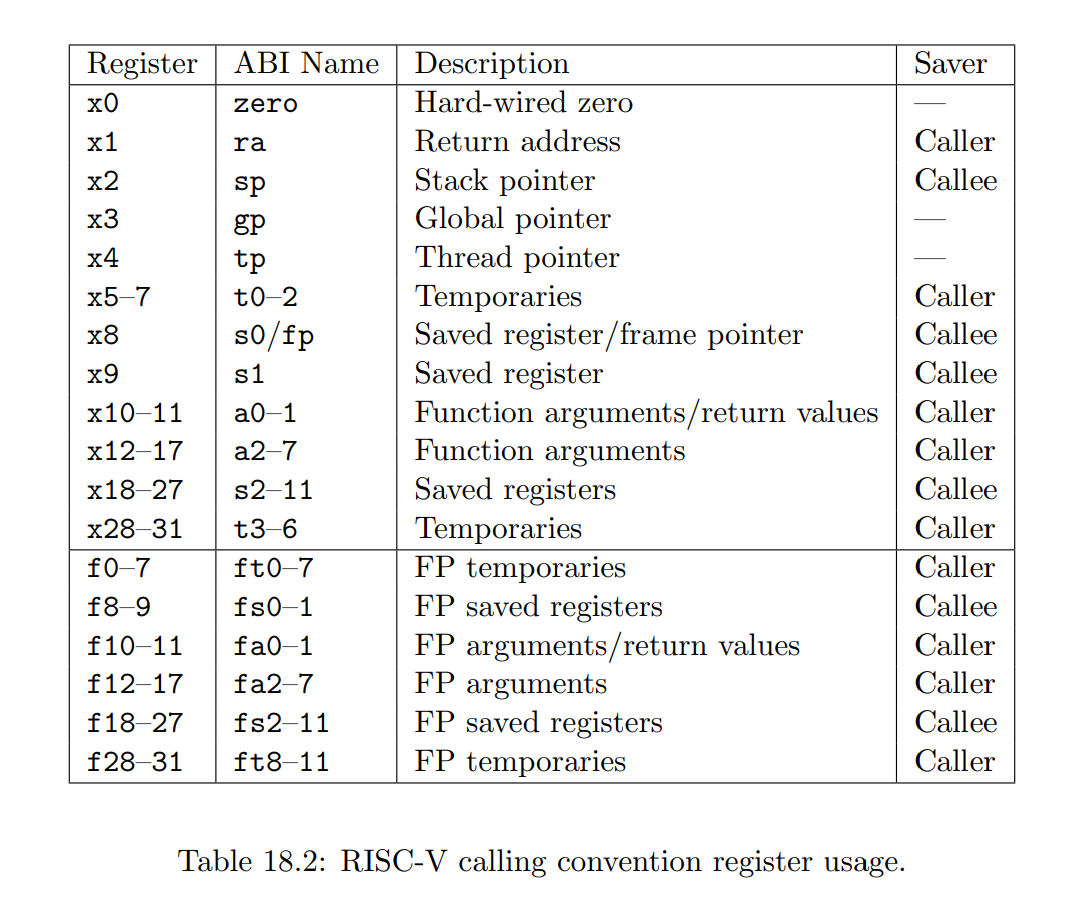
在 ABI Name 那一列,可以看到 s0 其实就是 fp 的别名。
有了这些知识,就可以写出 backtrace() 这个函数了:
1 | void |
可以看到这里用了一些很奇怪的写法,好像是负数下标的数字,其实这个 cur_frame[-1] 等价于 *(cur_frame - 1)。并且,因为这里 cur_frame 是六十四位的指针,所以 *(cur_frame - 1) 是读取 cur_frame 前八个字节位置的数据。
这里使用 PGROUNDDOWN 和 PGROUNDUP 是因为,一连串的函数调用最多放在一个页中。那么如果我们在递归打印的时候,超出了这一页的范围,就可以说明已经是最底层的函数,可以停止了。
最后我们按照要求在 sys_sleep() 这个系统调用里添加一下 backtrace(),就完成这个 lab 了。
Alarm
实现一个sigalarm(interval, handler)的系统调用。及每过 interval 个时钟周期,就执行一遍 handler 这个函数。此外还要实现一个sigreturn()系统调用,如果 handler 调用了这个系统调用,就应该停止执行 handler 这个函数,然后恢复正常的执行顺序。如果说sigalarm的两个参数都为 0,就代表停止执行 handler 函数。
其实理解这个 lab 还是挺难的,特别是 sigreturn,具体可以看看 alarmtest.c 这个程序,然后就是,需要对陷入的过程有比较好的理解,如果不熟悉,可以看看我的这篇文章:
1 | void |
这个 sigreturn 的意思就是,我们本来可能在执行这个 for 循环中的代码,然后突然开始执行 periodic() 这个函数(因为时间到了)。如果在 periodic() 函数中调用了 sigreturn()。就应该停止执行 periodic() 里的东西,然后回到 for 循环中执行。(可以看这个 up 主讲的,比较清晰)
这里我们可以依次查看 alarmtest.c 中的几个 test(或者说就是测试点),然后按照这些测试点的要求去实现这个系统调用。
test0: invoke handler
Get started by modifying the kernel to jump to the alarm handler in user space, which will cause test0 to print “alarm!”. Don’t worry yet what happens after the “alarm!” output; it’s OK for now if your program crashes after printing “alarm!”. Here are some hints:
大概就是说,我们可以先尝试去正确的跳转到用户态去执行 handler 函数(为了保持隔离性,不能在内核里直接把这个函数执行了),如果跳转之后报错了也没关系。
首先可以回忆下 xv6 发生陷入的过程,我们是根据 epc 这个寄存器来判断陷入之后返回的地址的。如果直接改变了 epc 的地址,就可以在返回的之后跳转到 handler 的地址。
那如何判断时候到了要跳转的时间呢?
riscv 的硬件(其实我不太确定是哪个硬件)会每过一个时钟周期都产生一个时钟中断,而 trap.c 会处理这个中断。
我们可以依靠这个中断出现的次数去判断是否应该跳转,如果需要,就直接在 trap.c 中把 trapframe 里 epc 的值改了(改成 handler 的)。
因此需要在 struct proc 给每个进程加入如下的属性:
uint64 alarm_tks;用于记录执行 handler 的间隔,如果为 0 代表不执行void (*alarm_handler)();handler 的地址uint64 alarm_tk_elapsed;距离上次执行 handler 过去的时间
并且在 sys_sigalarm() 把获取到的这些参数存入这些属性中,对于 sys_sigreturn(),我们先不做任何操作,直接返回一个 0:
1 | uint64 |
相应的,我们创建了这些属性,就需要在进程的初始化函数 allocporc() 和释放函数 freeproc() 中做相应的初始化和释放。
首先是 allocporc() 的改动:
1 | …… |
然后是 freeproc():
1 | …… |
接下来就可以在 trap.c 的 usertrap() 中函数实现跳转了:
1 | …… |
这样我们就能顺利的跳转到 handler,并且通过 test0,当然也毫无悬念的报错了。
报错的主要原因是还没实现 sys_sigreturn(),这样在执行完 handler 函数之后就不知道返回哪里了。
而要通过 test1 和 test2 就必须解决这个问题:
test1/test2(): resume interrupted code
Chances are that alarmtest crashes in test0 or test1 after it prints “alarm!”, or that alarmtest (eventually) prints “test1 failed”, or that alarmtest exits without printing “test1 passed”. To fix this, you must ensure that, when the alarm handler is done, control returns to the instruction at which the user program was originally interrupted by the timer interrupt. You must ensure that the register contents are restored to the values they held at the time of the interrupt, so that the user program can continue undisturbed after the alarm. Finally, you should “re-arm” the alarm counter after each time it goes off, so that the handler is called periodically.
大概的意思是,我们需要在执行完 handler 后返回到正确的位置。
需要注意的是,我们跳转到内核去响应陷入和系统调用时,寄存器的值是会改变的,这样就算通过改变 epc 的值回到了正确的位置,也不能正确的执行(没有把寄存器的环境备份下来)。
因此我们在 struct proc 再加一个 struct trapframe 类的属性,用于备份执行 handler 前的环境:
1 | …… |
当然,在 allocproc() 和 freeproc() 中的初始化和释放也是少不了的:
allocproc():
1 | …… |
freeproc():
1 | if(p->alarmframe) |
alarmframe 可以在 trap.c 里的 usertrap() 获取,也就是需要执行 handler 的时候,我们先备份一下环境,然后再执行:
1 | if(which_dev == 2){ |
在 sys_sigreturn() 里面,我们应该去按照 alarmframe 恢复 trapframe,这样包括 epc 在内的所有通用寄存器都会被恢复,自然也就会跳出 handler,按照原来的顺序执行程序了:
1 | uint64 |
到这里,我们再去运行 alarmtest,会发现还是不能完全过。
试想这样一个情况,如果 handler 执行的特别慢,自从上次调用 handler 已经过去了规定的时钟周期,但是 handler 还没执行好,这个时候我们又去改一遍 epc,这个 handler 又从头开始执行了,那着不就出大问题了,因为我们每次都会去改 epc,然后就永远执行不完 handler 了。
测试程序里就包括了这个情况:
1 | void |
所以我们需要在 struct proc 里再加一个属性,就是 alarm_state。如果这个属性为 1,就表示,handler 程序正在执行,这个时候就算又过了 tick 个时钟周期,我们也不能去改 epc 让 handler 重复执行。
因为新添加了一个属性,所以 allocproc 和 freeproc 也需要改,这里就不细讲了。
更重要的还是要更改 usertrap() 函数中的东西:
1 | if(which_dev == 2){ |
同时,sys_sigreturn() 函数里的东西也要改,因为调用了这个函数就代表 handler 不再执行了:
1 | uint64 |
改完之后就能成功 AC 了,也祝现在做这个实验的人尽快 AC:
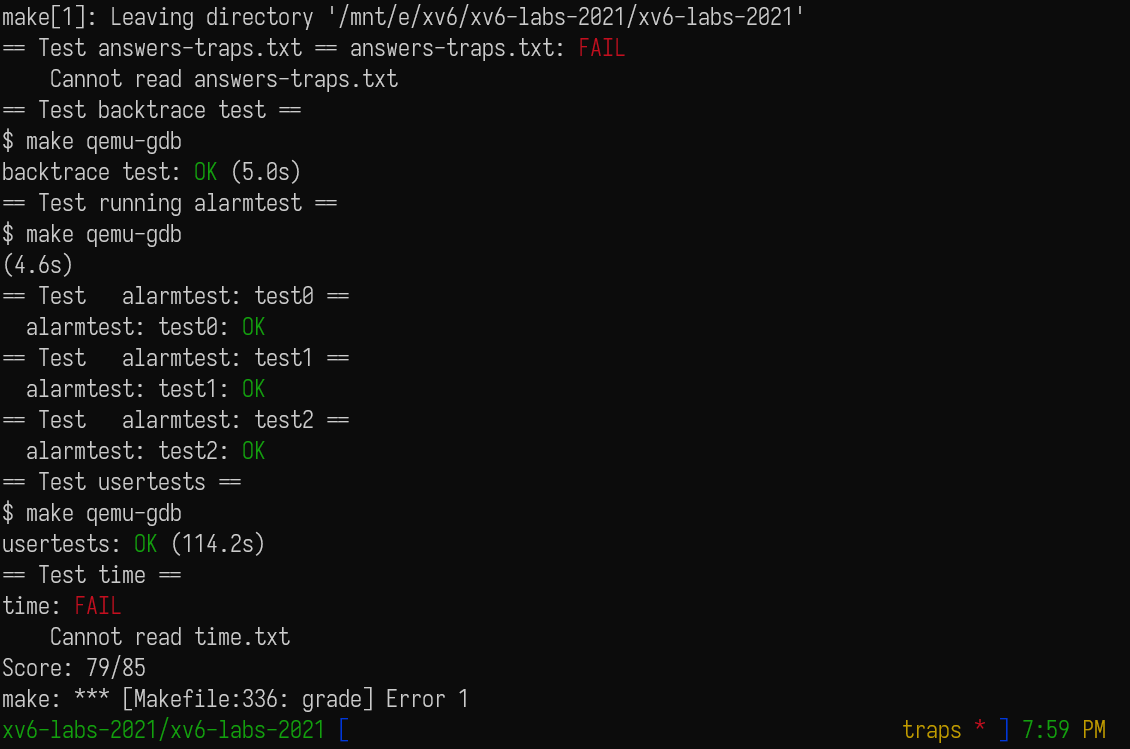
总结
比起这里的实验,其实更重要的还是理解 xv6 中陷入的过程,就算没有完全理解陷入过程,也能一步一步的照着实验指导做出这些实验。当然,要理解这里的陷入机制也属实是令人头疼,毕竟有很多以前从来没接触过的 riscv 汇编和底层的知识。虽然难理解,但理解和完成实验后,会让人不由自主的感叹操作系统设计的巧妙。
做完这个实验后,以前很多对操作系统的疑问也解决了,比如像 alarm 实验的原理。同时,也发现自己对汇编的理解还很浅。具体可以看 xv6 笔记那篇文章,一直理解不了为什么 userret 和 uservec 里要交换 sscratch 寄存器,后来问了才知道这个是特权级寄存器,不能用 ld,和 sd 这样的指令操作(实际上现在也没理解这样设计的原因)。




![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)