[MIT 6.s081] Xv6 Lab7 Multithreading 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里:
https://github.com/ttzytt/xv6-riscv
里面不同的分支就是不同的实验。
Lab7: Multithreading
Uthread
实现用户态线程。

因为我们要实现用户态的多线程机制,所以很大程度上可以参考内核态中多线程的实现。
查看 user/uthread.c 后可以发现,基本的框架已经给我们写好了,我们只需要实现一些函数的内容就行了。
那不如先把函数中要实现的内容写出来:
thread_switch(): 这个函数和内核中的swtch()完全一样,用于切换处理器的上下文。和内核中相同(参考这篇文章),因为执行这个函数的过程是一个正常的函数调用,所以我们不需要保存和交换调用者保存的寄存器。thread_create():这个函数是用于创建新的用户线程的。参考内核态多线程的实现。我们调用swtch()后,决定跳转位置的是 ra 寄存器,决定恢复出来的被调用者保存寄存器的是 sp 寄存器。所以,在这个函数中,我们应该合理的设置 ra 寄存器,使得第一次执行用户函数时,是这个函数的第一条语句。thread_schedule():参考内核中的实现,这个函数和内核中的scheduler()的作用相同。也就是在当前进程调用yield()后,找到一个 RUNNABLE 的进程,然后执行这个进程。在thread_schedule()中,我们会需要调用thread_switch()来切换处理器的上下文。
这样我们就大概的把各个函数的功能和实现思路理清楚了,接下来可以从第一个函数开始实际的实现。
首先我们要注意到,utrhead.c 原本的文件中并没有给 struct thread 加上一个上下文的属性,所以我们给他加上,上下文保存的寄存器和内核态多线程中完全相同:
1 | struct Context{ |
然后 thread_switch() 差不多就可以直接把 swtch() 中的东西抄过来了:
1 | .text |
那这个函数我们就写完了。
接下来是 thread_create()。实现这个函数主要需要思考如何设置 ra 和 sp 寄存器。因为用户进程一开始的时候是没有使用寄存器的,所以如何设置上下文中的其他寄存器是无所谓的。
首先,在 thread_create() 之后,如果我们调用了 thread_schedule() ,应该执行的是线程函数的第一个语句。所以我们可以这么设置 ra:
1 | t->ctx.ra = (uint64) func; |
对于 sp,我们需要注意的是栈是从高地址到低地址增长的(我一开始没想到),那么 sp 应该被设置在栈的最高地址:
1 | t->ctx.sp = (uint64) &t->stack + (STACK_SIZE - 1); |
那么这个 thread_create() 就写完了:
1 | void |
接下来可以处理 thread_schedule():
观察原来函数的代码可以看到,最开始的循环找到了第一个为 RUNNABLE 的线程,然后把这个线程赋值到 next_thread()。所以很明显,我们应该交换 current_thread 和 next_thread() 的上下文。
不过这个函数有个比较坑的地方,就是在交换前写了这个东西:
1 | t = current_thread; |
那我们就需要交换 t 和 next_thread 了:
1 | thread_switch((uint64) &t->ctx, (uint64) &next_thread->ctx); |
完整代码如下:
1 | void |
看了别人的一些博客[1]后发现,这里实现的用户态多线程其实更接近协程。因为这里的线程是自愿交出处理器资源的,而不是靠定时器中断,同时,使用的核心也只有一个。
或者说,这里的函数可以把自己挂起,然后过一段时间再通过 thread_schedule() 来恢复执行。
以前看了一些协程的东西,基本上只能理解为什么协程被称作“可以被挂起的函数”,而不能理解,为什么协程是“用户态线程”,更搞不懂协程是怎么实现的。
这个感觉还是挺奇怪也挺爽的,就是在学另一个知识的时候,把以前一直都搞不懂的,看似不相关的东西给搞懂了。所以花了很久时间没学懂的时候可以先放一放,说不定以后不知道什么时候就搞懂了。
Using threads
这个 lab 的描述还是挺长的,所以我就不放图片了。大概就是让我们阅读一个散列表(哈希表)的程序,然后做一些更改,使得这个程序在多线程的环境下也可用。
可以尝试运行下提供给我们的程序,如果只使用一个线程,那么一切正常。如果改成两个及以上,就会发现某些在散列表中插入的键值对直接消失不见了。
为了解决这个问题,我们可以先看一遍这个散列表,找一找问题出现的地方。这个程序中,最关键的有三个函数 insert(),put() 和 get()。我们可以一个接一个看:
首先是 insert():
1 | static void |
我们知道,在散列表中,如果哈希函数把多个不同的键映射到了同一个位置,就会需要把这个当作链表的形式,在查找时遍历这个链表来找到正确的键值对。
这个 insert() 函数做的就是在链表中插入元素的工作。其中,e 是一个新被插入链表 *p 中的元素,我们先利用参数初始化了 e 的各个属性。
特别需要注意的是 e->next = n 这句话,这里的 n 是链表 table[i] 或者说 *p 的第一个元素,那么 e->next = n 就意味着现在把 e 插入在 *p 的前面。
下一个函数是 put():
1 | static |
其实就是尝试在散列表中添加一个键值对。这个函数会先尝试查找散列表中是否存在某个 key 如果存在,就用 value 替代掉原来和 key 对应的值。
如果不存在,就调用 insert() 函数插入该键值对。
最后一个重要的函数是 get():
1 | static struct entry* |
也就是说,遍历散列表中的对应链表,来查找值对应的键。
总的来说,这是一个比较常规的散列表实现,看似没有任何问题,但是在多线程环境下会出现一些 bug。
考虑这样一种情况[1]:
有两个键 k1 和 k2,他们属于散列表中的同一链表,并且链表中都还不存在这两个键值对。现在有两个线程 t1 和 t2,它们分别尝试在该链表中插入这两个键值。
那么有如下的可能情况:
t1 先检查了链表中不存在 k1,于是准备调用 insert() 在链表前插入键值对。
这个时候,线程调度器切换到了 t2(也可能是在多核环境下,两个线程并行执行,但是 t2 比 t1 快)。
然后 t2 也发现了链表中不存在 k2,所以调用 insert() 插入。插入之后,k2 成了链表的第一个元素。
随后 t1 也真正的插入了 k1。但是,因为 t1 并不知道 t2 已经把 k2 插入到了开头,于是在其认为的链表开头(k2 所处位置)插入了 k1,k2 就被覆盖掉了,于是造成了键值对丢失。
这样的情况下,我们需要通过加锁来解决问题。
观察前面的情况,可以发现,对于每一个散列表,在每一个时刻,只能由一个线程来操作,这里的操作包括了读取和修改。因为如果有多个线程,可能会造成某些线程获到的信息是滞后的(如前面的情况)。
所以我们可以对于散列表中的每个链表都创建一个互斥锁,然后在 put() 和 get() 的开头和结尾加锁和解锁。
那为啥不在 insert() 里加锁呢?因为 insert() 都是 put() 调用的,对于一个互斥锁,这样就会造成死锁。
所以就可以这样修改 put() 和 get():
1 | pthread_mutex_t bkt_lock[NBUCKET]; |
Barrier
实现同步屏障。
先简单解释一下同步屏障是个什么东西。根据维基百科:
同步屏障(Barrier)是并行计算中的一种同步方法。对于一群进程或线程,程序中的一个同步屏障意味着任何线程/进程执行到此后必须等待,直到所有线程/进程都到达此点才可继续执行下文。
那么一个朴素的实现方法就是在一个线程到达屏障时把某个变量 +1,最后如果这个变量等于线程总数量,就可以执行了。
当然,在变量到达总数量前,我们需要让线程阻塞在屏障的位置。同时,当变量符合条件后,阻塞的线程就可以越过屏障了。
我们当然可以使用互斥锁加上轮询的方式来检查变量是否符合条件,但是这样对性能的损失是比较大的。
这样轮询的方法是被动的,也就是每个线程都去询问,那为何不让最后一个到达屏障的线程去通知其他线程呢?
pthread 库函中的条件变量实现的就是这样的功能。
举个例子,如果我们调用了 pthread_cond_wait(&cond, &mutex),那么在最后一个线程调用 pthread_cond_broadcast(&cond) 之前,程序就会一直阻塞。
更具体的,pthread_cond_wait(&cond, &mutex) 按照顺序干了下面的事情:
- pthread_mutex_unlock(&mutex);
- 把线程放入等待条件的线程列表上
- 阻塞线程(直到别的线程发送信号)。
注意 1 和 2 是原子的操作。
如果有线程用条件变量发出了信号,那么:
- 内核会唤醒等待的线程(唤醒的数量取决于用的是 signal 还是 broadcast)
- 被唤醒的线程中,
pthread_cond_wait()会返回。 mutex再次被锁住
至于为什么条件变量一定要和一个互斥锁配合,在这里把我自己目前的认识写一下。
条件变量通常是要和一个别的变量配合着使用的,我们这里就叫这个变量 x 吧。
在调用 wait() 之前,我们肯定会先判断以下 x 是否符合一定的条件,如果符合了,那我们也没必要用 wait() 了。
如果不符合,我们会调用 wait(),这样一旦 x 符合了条件,我们就会知道。
但是这里这个普通变量 x 一定是在多线程的环境下被使用的。那么我们在调用 wait() 之前,检查 x 的时候,就要确保我们拿到了一个保护 x 的锁。
然后调用 wait() 后,发现 x 不符合条件,那肯定是要把锁释放出来的,要不然,别的线程也没办法修改 x 使其符合条件。
相同的,如果 x 符合了条件,wait() 会返回,这个时候会拿到保护 x 的锁。因为我们也许会修改 x ,或者使用 x,如果这个时候 x 被改变了,会出问题。
那为啥要把解锁和加入等待队列做成原子操作呢?
假设有这样一个使用条件变量的程序,并且其使用的条件变量没有把解锁和加入等待队列做成原子操作[2]:
1 | lock(x_lock) // 拿到保护 x 的锁 |
那么万一,在 unlock(x_lock) 之后,把当前线程放入 cond 的等待队列之前。有一个线程更改了 x 的值,并且发出了信号,当前线程就因为没被加入到等待队列,错过了这个信号。
所以必须要把放入队列和解锁做成原子操作。
艹,没想到写着写着光条件变量就扯了这么多,同步屏障倒是一点没讲。现在进入正题,来具体实现同步屏障。
我们观察一下 barrier.c 中提供的 barrier 结构体:
1 | struct barrier { |
可以看到这里的 nthread 就是之前我们提到的 “x”,因为只有不符合 nthread,我们才会调用条件变量的 wait()。
然后,对应的,保护 x 的锁就是 barrier_mutex。这样的话,就可以写出下面的程序了:
1 | static void |
这里需要注意一个细节,就是 pthread_cond_broadcast() 和 pthread_cond_signal() 的区别。
如果我们用了 broadcast(),那所有在等待列表中的线程都会被唤醒,反之,signal() 只会唤醒列表中的一个线程。
在我们的情况中,如果最后一个线程执行到了屏障,那所有的线程都可以继续往下执行,所以用了 broadcast()。
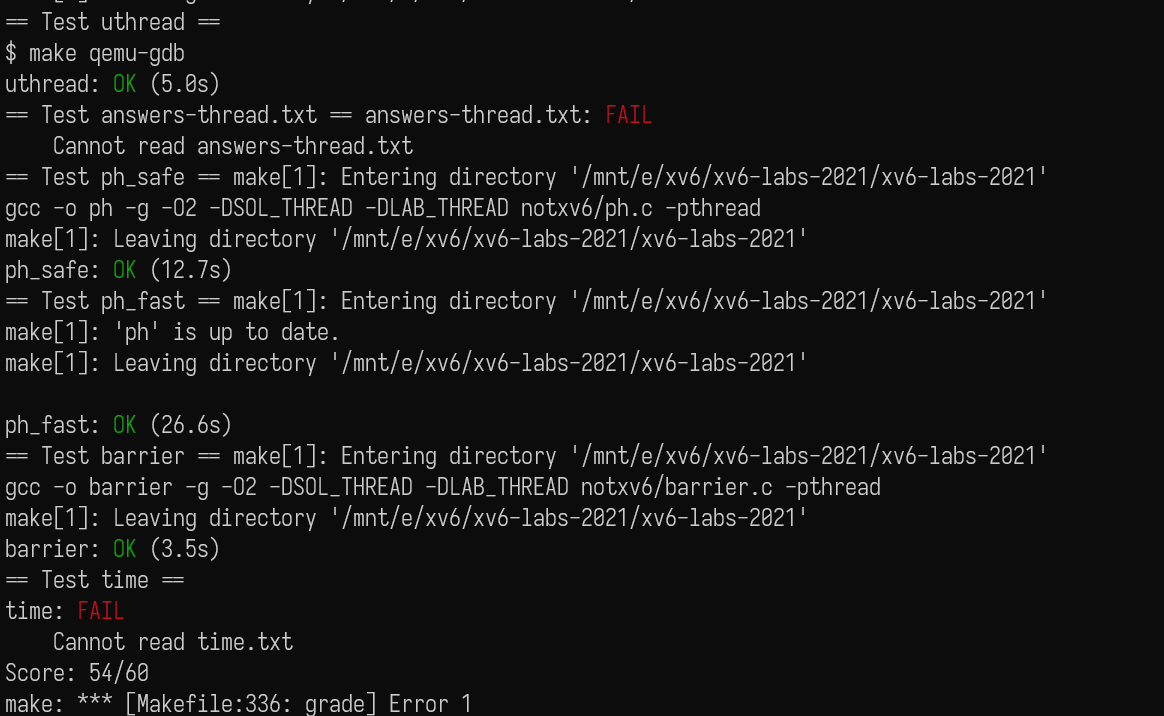
然后我们就可以愉快的 AC 了,也祝在做这个 lab 的人尽快 AC:
总结
发现写博客还是挺重要的。有的时候把代码搞出来了不一定代表完全懂了。比如最后一个 lab 的条件变量。写的时候只是懂了他干的事情,感觉没问题。但是写博客时,就发现不知道如何解释,于是只能去查更多的资料。这大概说明了,如果想给别人讲清楚某个知识,需要对这个知识有更深刻的理解。
其次,这个 lab 的代码量是比较小的(说实话到目前为止还没做到过码量特别多的 lab)。如果没有完全理解 xv6 中线程调度和切换的原理,也能做出来。但完全理解后再做这个 lab,就能有更好的理解(特别是 uthread 那个实验,剩下两个还是跟 pthread 库的关系更多点)。



![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)