[MIT 6.s081] Xv6 Lab8 Networking 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里:
https://github.com/ttzytt/xv6-riscv
里面不同的分支就是不同的实验。
Lab8: Networking
这个 lab 的描述属实是长,不过很多的篇幅都在介绍 E1000 网卡。最终的任务其实很简单,就是实现 E1000 网卡驱动中的 transmit() 和 recv() 函数。
这个 lab 的代码不复杂,但写出来需要对 lab 中的提示有很好的理解。同时,也需要查阅 E1000 的文档。
下面先介绍处理器和 E1000 交互的方法,随后再介绍两个函数的具体实现方法。
E1000 的交互方法
E1000 使用了 DMA(direct memory access)技术,可以直接把接收到的数据包写入计算机的内存,这在数据量大的时候非常有用,可以当作缓存。
在发送时也可以把描述符(见下文)写入内存的特定位置,这样 E1000 就会自己去找到待发送的数据,然后发送。
不管是接收还是发送,数据包都是以描述符数组描述的。在下面的接收和发送部分,会分别介绍接收描述符和发送描述符的格式。
接收
如果网卡收到了数据,会产生一个中断,然后调用对应的中断处理程序去处理这个新到达的数据。
描述符
接收描述符的格式如下:
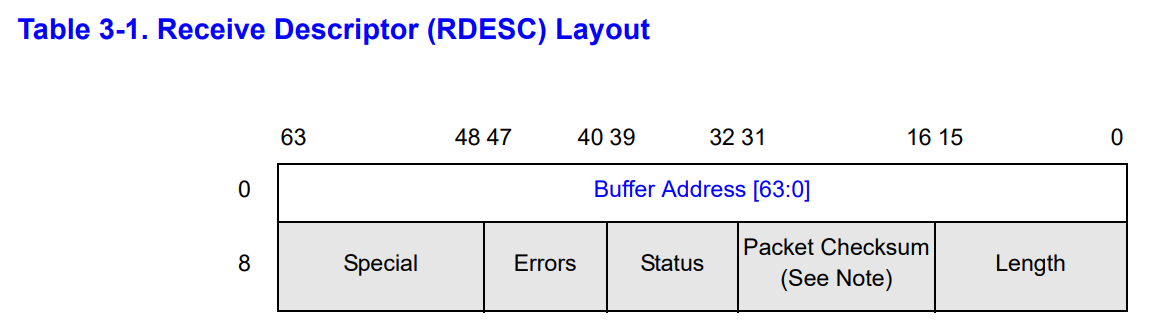
在 xv6 中,这个描述符的定义如下:
1 | // [E1000 3.2.3] |
我们会在内存中放一个数组的描述符,然后这个数组会被解读成一个环形队列。
如果网卡接收到了一个新的数据包,会检查环形队列 head 位置的描述符。然后把数据写入 head 描述符的缓冲区,也就是 addr 记录的地址。
这里比较重要的还有 status 和 length 属性。网卡在写入的时候就会设置这些属性。
其中,length 表示写入 addr 的数据包长度。status 则可以代表下列状态:
其中,我们需要用到的主要是 DD (Descriptor Done) 这个标志位。其表示网卡已经接收好了这个包。
在编写驱动的过程中,我们需要注意判断这个标志位,如果还没有完全接收好,我们就应该继续等待一段时间。
环形队列
上面我们提到了,如果网卡收到了新的数据,会往环形队列 head 位置描述符的缓冲区写入数据,下面来讨论网卡和驱动程序是如何具体管理这个缓冲区的。
下图展示了接收描述符环形队列的结构:
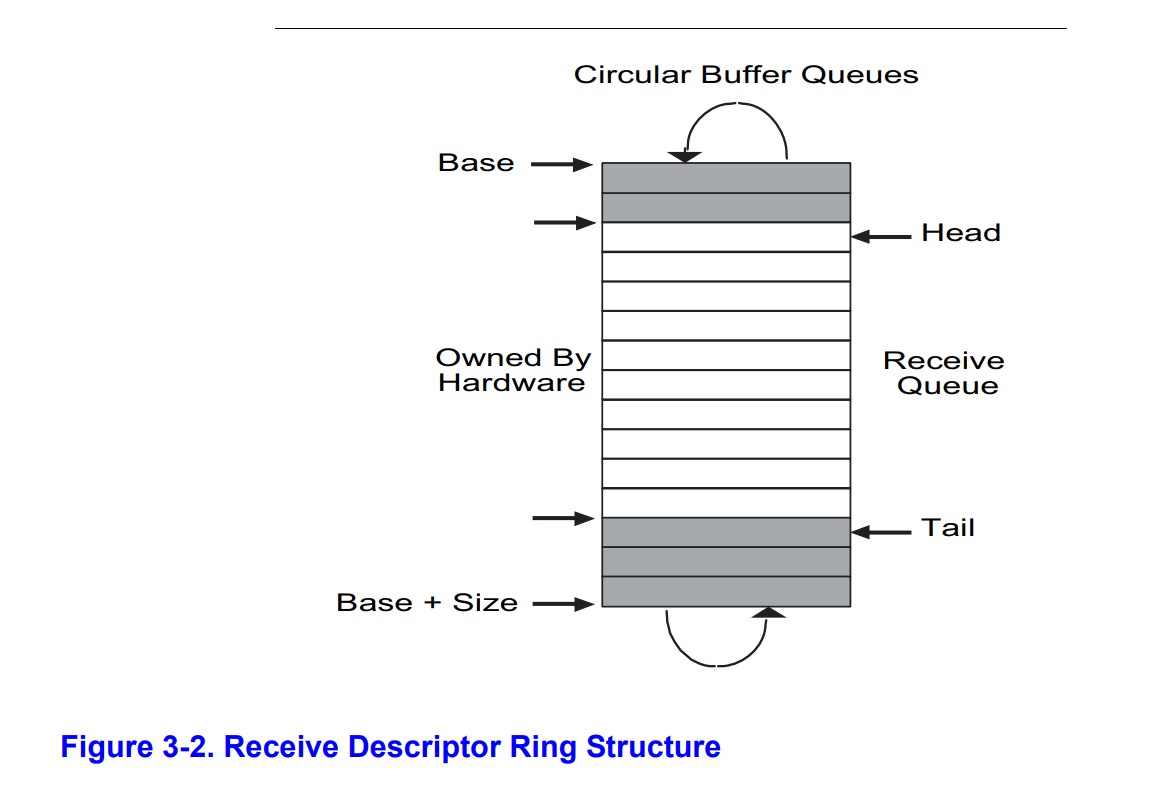
初始化时,head 为 0,tail 为队列缓冲区减一。
其中,head 到 tail 的这段浅色的区域是空闲的(图好像有点问题,其实 tail 指向的位置也时空闲的)。也就是说,这个区域内的数据包都已经被软件处理好了,那么如果有新的数据包到达,网卡会把数据写入这个区域的开始,也就是 head,把老的数据覆盖掉。网卡把老的数据覆盖掉后会把 head 的值加一。
而软件会按照顺序处理深色的区域。读取环形队列时,读取的是 tail + 1 位置描述符缓冲区的数据(这个位置是所有未处理数据中等待时间最长的),处理完这个缓冲区后会把 tail 增加一。
发送
描述符
发送描述符的格式如下:
在 xv6 中,这个描述符的定义如下:
1 | // [E1000 3.3.3] |
其中 addr 和 length 的作用和接收描述符的作用相同,这里不赘述。
除了这两个,我们主要还需要用到 cmd 和 status 这两个属性。
和接收标志位一样,在 status 中我们需要用到 DD 标志位,表示当前标志位指向的数据是否发送完成。
而 cmd 描述了传输这个数据包时的一些设置,或者说对于网卡的命令。
有以下的命令可以选择:
这里需要用到的命令有如下几个:
- RPS (Report Packet Sent):设置之后,网卡会报告数据包发送的状态。比如,在描述符指向的数据发送完成后,网卡会设置描述符的 DD 标志位。
- EOP (End of Packet):表明这个描述符是数据包的结尾。如果要发送的数据包特别大,我们可能会用很多个描述符的缓存空间来储存一个包。那么可以给这个数据包的最后一个描述符设置 EOP 命令。只有这样才能给这个描述符加上一些别的功能,如 IC,即加入和校验。
环形队列
和接收描述符的环形队列略有不同,发送描述符的 head 到 tail 这段区域(途中浅色区域)表示我们希望发送,但是网卡还没发送出去的数据。
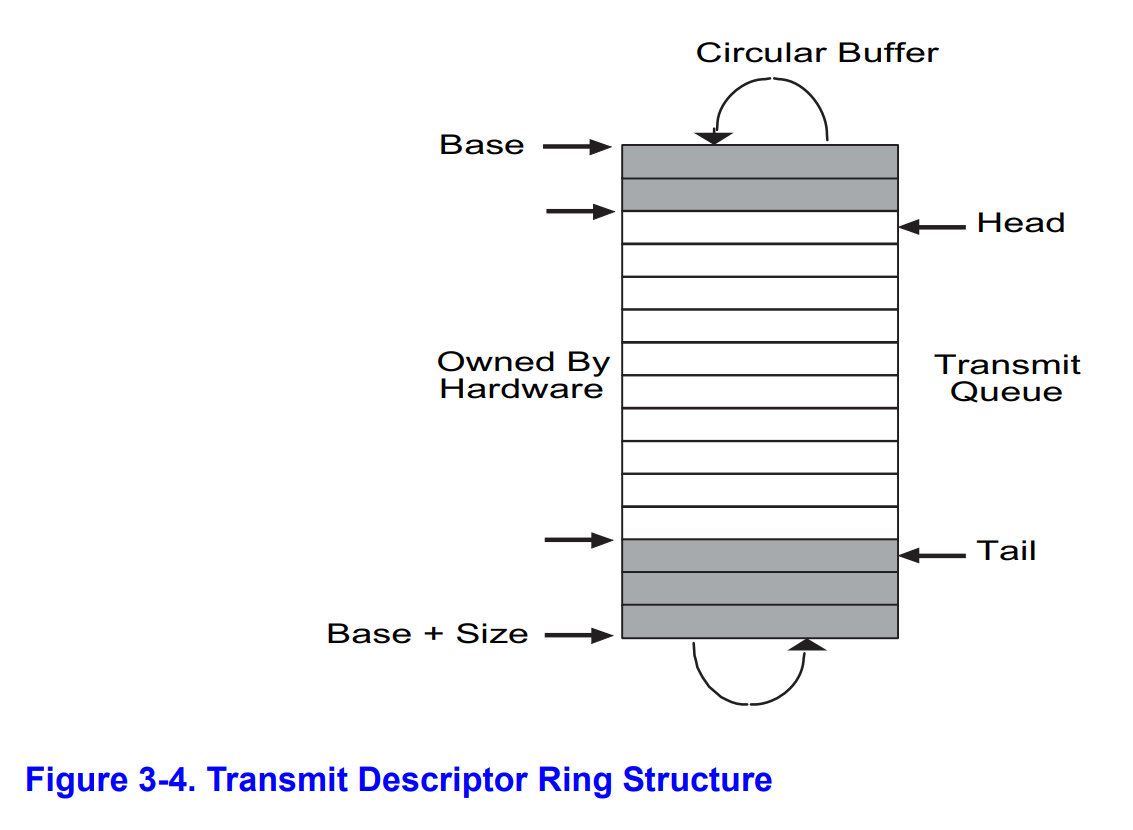
其中 head 指向等待时间最长的待发送数据,网卡会从这里开始发送。完成后会把 tail 加一而如果我们要新加入一个描述符,是从 tail 这个方向加入的,也会把 tail 加一。
xv6 对网络数据的描述
为了方便网络数据的处理,xv6 还定义了一个结构体,即 struct mbuf,如下:
1 | struct mbuf { |
在 e1000_transmit() 函数中,我们就需要接收一个 mbuf 类型的网络数据,然后写入 DMA 对应的内存地址,进而让网卡发送这个数据。
mbuf 的结构大致是下面这样的:
1 | // The above functions manipulate the size and position of the buffer: |
其中的 headroom 可以被 push 进去,用来储存网络协议的包头。在接收网络数据后也可以把中间 buffer 的部分 pull 进去来转换成如下的包头:
1 | // an Ethernet packet header (start of the packet). |
转换的部分可以在 net_rx() 函数找到:
1 | struct eth *ethhdr; |
而 buffer 部分是数据正文,剩下的 tailroom 是 char buf[MBUF_SIZE] 这个缓存除去前两部分的剩下部分。
在 struct mbuf 结构体中,len 表示正文的长度,head 表示 headroom 的结束位置。
在 net.c 中有很多和 mbuf 相关的函数,最主要的就是 mbufalloc() 和 mbuffree() 分别对应着 mbuf 的分配和释放。
寄存器操作
我们可以通过特定的内存映射访问到 E1000 的控制寄存器。具体来说,是通过 e1000.c 中的 regs 全局变量加上一些偏移量。在 e1000_dev.h 中定义了额这些偏移量。
代码实现和解释
发送
思路大概是这样的(其实就是 lab 中的提示)。
首先通过内存映射的控制寄存器得到当前环形队列的 tail(第一个没在发送的描述符位置)。然后取得 tail 对应的描述符,如下:
1 | acquire(&e1000_lock); // 可能多个线程同时发送,所以要加锁 |
然后检测当前描述符的状态。如果没有 E1000_TXD_STAT_DD 这个标志位,说明这一整个队列已经没有空闲的位置了(或者说这个 tail 已经碰到了环形队列的浅色区域了,也就是整个队列都储存了待发送的描述符)。在这种情况下,我们需要直接返回。
1 | if(!(desc->status & E1000_TXD_STAT_DD)){ // 是否传输完成,没传完的话说明环形缓冲区没了,是错误 |
接下来需要检测这个描述符对应的 mbuf 的状态。描述符的 addr 属性会指向这个 mbuf,如果这个描述符中的数据(也就是对应的 mbuf)已经发送完了,那就可以把这个 mbuf 释放掉。
1 | if(tx_mbufs[idx] != NULL){ // 这里的 buf 指向要发的数据包 |
老的释放掉之后就可以让描述符的 addr 指向当前要发送的数据了。并且还需要更新数据长度,如下:
1 | desc->addr = m->head; |
这里有个地方我花了很久才搞懂,就是为什么要写 desc->addr = m->head,而不是 desc->addr = m->buf。
我一开始以为 mbuf 的 headroom 就是储存数据包头的。实际上,真正储存包头的部分是 mbuf 中间 buffer 的开头。而 headroom 只是一个“缓冲区”。比如如果我们需要把当前的包头换成另一个占用空间更大的包头,就可以先调用 mbufpullhdr() 再调用 mbufpushhdr()。
我们可以看一个别函数调用 e1000_transmit() 的例子来了解 headroom 的作用。整个 net.c 中只有 net_tx_eth() 一个函数调用了 e1000_transmit()。如下:
1 | // sends an ethernet packet |
这个函数的主要作用就是给以太网的数据包加上包头。ethhdr = mbufpushhdr(m, *ethhdr); 这句话缩小了 headroom 的大小,增加了 buffer 的大小。并且把增加出来的这部分空间赋值到了 ethhdr 上。
然后接下来的 memmove(ethhdr->shost, local_mac, ETHADDR_LEN); 和 memmove(ethhdr->dhost, broadcast_mac, ETHADDR_LEN); 就把数据头复制到了这个新在 headroom 中开辟出来的空间。这样 mbuf 的 buffer 部分就包括了数据头。
如果之后有更大的数据头,还可以缩小 headroom 增加 buffer 来存放。
回到 e1000_transmit() 函数的实现,在更新好描述符的 addr 和 len 后,还需要设置对这个描述符的命令:
1 | desc->cmd = E1000_TXD_CMD_RS | E1000_TXD_CMD_EOP; |
这里的两个命令在前面发送描述符的部分已经解释过了,这里不赘述。
e1000_transmit() 的最后一点代码如下:
1 | tx_mbufs[idx] = m; // 方便之后清理 |
这里主要解释 tx_mbufs[idx] = m; 这句话。回想我们在该函数的前面部分检查了描述符的 E1000_TXD_STAT_DD 标志位,其表明网卡是否发送完成了这个描述符的数据。如果没有,我们会直接退出。如果有则清理这个数据缓存。
那么我们设置 tx_mbufs[idx] = m 就是为了方便检测这个标志,由此跟踪数据发送的状态。
e1000_transmit() 的完整代码如下:
1 | int |
接收
首先要注意的一点是,在 e1000_recv() 中,我们需要一次性读出所有的待读取数据包。也就是需要加一个循环,然后一直读取 tail 位置的描述符,直到描述符的状态为未完成接收。
对于接收到的数据包,E1000 网卡有很多种不同的中断策略。一般最常用的是 RDTR (Receive Interrupt Delay Timer 接收中断延迟计时?) 。大概就是收到一个包,并且用 DMA 写入宿主的内存后,会开启计时器,在到达设定的事件后发生中断。
这个策略的主要好处是可以减少大量包在短时间内到达时发生的中断次数。但是 xv6 中没有采用这个策略,而是每次写入宿主内存后都产生一次中断,相关的代码如下:
1 | regs[E1000_RDTR] = 0; // interrupt after every received packet (no timer) |
那如果使用了这样的终端策略,每次中断就只需要读取一个描述符啊,为什么需要循环的读取 tail。
我个人的理解是因为在处理这样外部设备中断的时候,我们会先关闭中断。
假设大量包在短时间内到达,那么产生第一个中断后,我们会去处理这个中断。处理过程中,可能又会产生很多中断,在这样的情况下我们是接收不到这些中断的,因为处理单个描述符的速度赶不上中断的速度。
所以就需要每次处理中断时再检查是否有别的到达的包,如果有就继续读取。
回到这个函数的实现,我们还是需要先读取 tail 的位置,然后取得对应的描述符:
1 | uint idx = (regs[E1000_RDT] + 1) % RX_RING_SIZE; // head 到 tail 是一个空的缓冲区 |
要注意的是 tail 本身也是一个空的缓冲区,其数据已经在之前被处理过,所以我们需要将 tail 加一。
接下来判断,是否读完了所有待读取的描述符,方法还是使用 DD 标志位:
1 | if(!(desc->status & E1000_RXD_STAT_DD)){ |
重新设置 mbuf 的长度:
1 | rx_mbufs[idx]->len = desc->length; |
和发送函数不同,这里的 mbuf 和描述符是一一对应的。也就是每个描述符的缓存都是一个之前设置好的 mbuf。这里描述符的 addr 已经被设置过了,具体的代码在初始化函数中(这是第一次的 mbuf,之后会覆盖掉):
1 | // [E1000 14.4] Receive initialization |
随后需要调用 net_rx() 函数把这个 mbuf 转发到相应的网络协议栈进行处理。
1 | net_rx(rx_mbufs[idx]); |
因为上层的协议栈还需要使用这个 mbuf,所以我们不能将其覆盖,需要给当前描述符分配一个新的 mbuf:
1 | rx_mbufs[idx] = mbufalloc(0); |
最后一步是更新 tail 指向的位置(注意 tail 本身是已经被软件处理过的描述符):
1 | regs[E1000_RDT] = idx; |
e1000_recv() 的完整代码如下:
1 | static void |
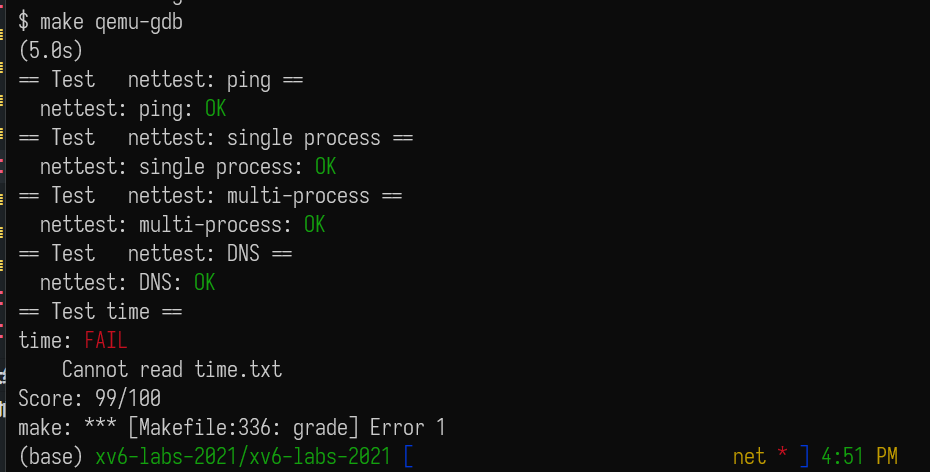
搞好了之后就可以顺利 AC 了:



![[Stanford CS144] Lab4 实验记录](/img/CS144/tcp%E7%8A%B6%E6%80%81%E6%B5%81%E8%BD%AC%E5%9B%BE.jpg)
![[Stanford CS144] Lab0-Lab3 实验记录](/img/CS144/sponge%E7%BB%93%E6%9E%84%E5%9B%BE.svg)