![[MIT 6.s081] Xv6 Lab11 Mmap 实验记录](/img/xv6/note/xv6%E4%B9%A6%E5%B0%81%E9%9D%A2.png)
[MIT 6.s081] Xv6 Lab11 Mmap 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 最后一个 lab 了,终于搞完了!! Lab11: mmap 描述 实现一个 UNIX 操作系统中常见系统调用 mmap() 和 munmap() 的子集。此系统调用会把文件映射到用户空间的内存,这样用户可以直接通过内存来修改和访问文件,会方便很多。 mmap() 的定义如下: 12void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); 意思是映射描述符为 fd 的文件,的前 length 个字节到 addr 开始的位置。并且加上 offset 的偏移量(即不从文件的开头映射)。 如果 addr 参数为 0,系统会自动分配一个空闲的内存区域来映射,并返回这个地址。 在实验中我们只需要支持 addr 和 offset 都为 0 的情况,也就是完全不用考虑用...
[MIT 6.s081] Xv6 Lab10 File System 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 Lab10: file system Large files 描述 在 xv6 的底层实现中,文件是由 struct dinode 来描述的,如下: 12345678struct dinode { short type; // File type short major; // Major device number (T_DEVICE only) short minor; // Minor device number (T_DEVICE only) short nlink; // Number of links to inode in file system uint size; // Size of file (bytes) uint addrs[NDIREC...
[MIT 6.s081] Xv6 Lab9 Lockss 实验记录
upd@2022/8/18: 本文的第二个实验不完全正确,并且还有很多其他的做法,具体可以见这篇博客中我和博主的讨论。以及博主根据讨论新写的代码。 如果接下来有时间,会把第二部分的代码改掉并添加注释。 upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 Lab9: locks Memory allocator 实验描述 这 lab 的描述也是非常长,所以就不截图了。下面描述一下大概的题意: 在原本的 kalloc() 中,只有一个大锁,我们会维护一个 freelist 链表,如果有任何程序申请内存,都需要竞争 freelist 的锁,以修改 freelist 的内容。具体可见 freelist 和 kalloc() 的实现: 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253struct ...
[MIT 6.s081] Xv6 Lab8 Networking 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 Lab8: Networking 这个 lab 的描述属实是长,不过很多的篇幅都在介绍 E1000 网卡。最终的任务其实很简单,就是实现 E1000 网卡驱动中的 transmit() 和 recv() 函数。 这个 lab 的代码不复杂,但写出来需要对 lab 中的提示有很好的理解。同时,也需要查阅 E1000 的文档。 下面先介绍处理器和 E1000 交互的方法,随后再介绍两个函数的具体实现方法。 E1000 的交互方法 E1000 使用了 DMA(direct memory access)技术,可以直接把接收到的数据包写入计算机的内存,这在数据量大的时候非常有用,可以当作缓存。 在发送时也可以把描述符(见下文)写入内存的特定位置,这样 E1000 就会自己去找到待发送的数据,然后发送。 不管是接收还是发送,数据包都是以描述符数组描述的。在下面的接收和发送部分,会分别介绍接收...
[MIT 6.s081] Xv6 Lab7 Multithreading 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 Lab7: Multithreading Uthread 实现用户态线程。 因为我们要实现用户态的多线程机制,所以很大程度上可以参考内核态中多线程的实现。 查看 user/uthread.c 后可以发现,基本的框架已经给我们写好了,我们只需要实现一些函数的内容就行了。 那不如先把函数中要实现的内容写出来: thread_switch(): 这个函数和内核中的 swtch() 完全一样,用于切换处理器的上下文。和内核中相同(参考这篇文章),因为执行这个函数的过程是一个正常的函数调用,所以我们不需要保存和交换调用者保存的寄存器。 thread_create() :这个函数是用于创建新的用户线程的。参考内核态多线程的实现。我们调用 swtch() 后,决定跳转位置的是 ra 寄存器,决定恢复出来的被调用者保存寄存器的是 sp 寄存器。所以,在这个函数中,我们应该合理的设置 ra...
[MIT 6.s081] Xv6 Lab6 COW 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 Lab6: Copy-on-Write Fork for xv6 这个 lab 的描述属实是简洁,其实他主要的描述在前面: The problem The fork() system call in xv6 copies all of the parent process’s user-space memory into the child. If the parent is large, copying can take a long time. Worse, the work is often largely wasted; for example, a fork() followed by exec() in the child will cause the child to discard the copied memory, probably without e...
[MIT 6.s081] Xv6 Lab5 (2020) Lazy Page Allocation 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 Lab5 (2020): lazy page allocation Eliminate allocation from sbrk() 删除 sbrk() 系统调用里实际分配内存的部分。 这个没啥好说的,直接按照提示信息,删掉对 growproc() 的调用就好了,如下: 1234567891011121314uint64sys_sbrk(void){ int addr; int n; if(argint(0, &n) < 0) return -1; addr = myproc()->sz;// if(growproc(n) < 0) <- 这里删掉实际申请内存的部分// return -1; myproc()->sz += n; // 但是把当前进程占用空间扩大 return addr;}...
[MIT 6.s081] Xv6 Lab4 Traps 实验记录
前言:今天是 2022/7/25 先庆祝一下博客运行 100 天了。 upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 Lab4: traps RISC-V assembly 先鸽了 Backtrace 实现一个 backtrace() 的函数,如果某个程序调用了这个函数,该函数应该输出这个程序的 “函数调用顺序”,也就是把当前栈中的函数地址按照先后顺序全部打印出来。 做这个实验最主要的还是需要了解函数调用的过程,具体可以参考我之前写的这篇文章。 这里我把那篇文章中最重要的图和视频放在下面(绝对不是水字数),如果你之前比较熟悉函数调用的过程,但是现在忘了,看了之后应该比较容易回忆起来。 实验中,我们需要把函数调用的一个 “链条” 打印出来。 比如有下面这个程序: 123456789101112131415int third(int x){ backtrace(); return x;
...
CC (Codechef) STARTERS 48 题解
Accurate XOR 思路 题目链接 这个题需要使用到一个异或的性质。我们可以发现,对多个 0 或 1 连续的异或时,只有出现奇数个 1 才能使运算结果为 1。 因为如果出现了偶数个 1,那么对于每一个 1,总是能找到另一个 1 让它们的异或值变为 0 。而 0 的出现不会影响最终的结果,所以如果出现了偶数个 1,最后的结果一定是 0 。 The Xor-value of a node is defined as the bitwise XOR of all the binary values present in the subtree of that node. 题面中的这一句话表明,一个树的异或值被定义为该树下每个节点的异或和。 或者说,设当前树的根节点为 rrr,rrr 有 xxx 个子节点(包括不直接的,比如其子树的孩子),这些子节点的值是 c1∼cxc_1 \sim c_xc1∼cx。那么 rrr 的异或值就是: XOR(r)=c1⊕c2…⊕cx−1⊕cx\operatorname{XOR}(r) = c_1 \oplus c_2 \ldots \op...
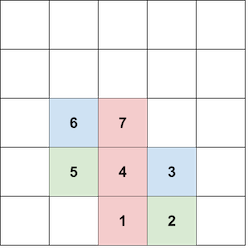
CF1705 B, C, D1 题解
B. Making Towers 思路 观察题面上给第一个样例提供的图: 可以发现,如果我们要让某种颜色形成一个塔,除非多个相同颜色在 ccc 数组中挨在一起,可以直接向上排布。就一定需要在排布该颜色后,向两侧放一些其他颜色,然后又往相反方向放置,最后使得两个颜色相同的块在一条直线上,大概是下面这样: 1234⬆->->->A⬆<-<-<-A<-<-<-⬆ A->->->⬆ 1 2 ... z 其中, AAA 表示一个颜色的塔,而箭头表示放置颜色块的路径。 观察发现,在放置两个 AAA 之间,需要放置偶数个其他颜色块,下面是解释: 假设第一个 AAA 的位置是 (x,y)(x, y)(x,y),并且我们往右侧放置的其他颜色块的数量是(也可以是左侧) zzz。 那么为了把第二个 AAA 搞到 (x,y+1)(x, y + 1)(x,y+1) 上,就需要在 (x+1,y)∼(x+z,y)(x + 1, y) \sim (x + z, y)(x+1,y)∼(x+z,y) 和 (x+1,...
CF1705 C, D 题解
C. Mark and His Unfinished Essay 思路 这个数据范围显然不能真的去复制字符串,所以要找到一些别的方法。 可以发现,每次在字符串末尾新加上的那一段,都可以通过一个偏移量在前面找到一模一样的。 比如我们可以观察样例中第一个数据的最后一次插入: mark mark mar rkmark\texttt{mark\ mark\ mar\ } \color{red}{\texttt{rkmark}} mark mark mar rkmark 把这个 rkmark\texttt{rkmark}rkmark 中的每个字母都向前移动 999 个位置,就是另一个 rkmark\texttt{rkmark}rkmark,如下: ma rkmark mar rkmark\texttt{ma\ } \textcolor{red}{\texttt{rkmark\ }}\texttt{mar\ } \textcolor{red}{\texttt{rkmark}} ma rkmark mar rkmark 所以我们可以维护一个三元组 (l,r,d)(l, r, d)(l,r,d...
[MIT 6.s081] Xv6 Lab3 (2021) Page Tables 实验记录
upd@2022/9/14:最近把实验的代码放到 github 上了,如果需要参考可以查看这里: https://github.com/ttzytt/xv6-riscv 里面不同的分支就是不同的实验。 注:和页表相关的基础知识在这篇文章中有说,可以参考。 Lab3: page tables Speed up system calls 为了加速系统调用,很多操作系统都会在用户空间内开辟一些只读的虚拟内存,内核会把一些数据分享在这里。这样就可以减少来回在用户态和内核态中切换的操作。我们需要用这个方法给 getpid() 加速。 这个 lab 的大概思路是,在创建进程时,就直接把进程的 pid 放入共享空间中,然后用户查询 pid 时,就不必通过 ecall 跳转到内核了,省去了保存现场等开销。 首先我们需要在用户态的虚拟内存中多添加一页,专门用于储存和内核共享的数据。 创建一个新的虚拟内存到物理内存的映射需要用到 mappages() 函数,这个函数在 kernel/vm.c 中实现: 123456789101112131415161718192021222324252627...

